21 - Engenharia de Software
21.1 - Processo de Desenvolvimento de Software.Software é um programa de computador que resolve um determinado problema. É composto de diversos módulos e componentes, estes subdivididos em funções e bibliotecas. O objetivo principal é receber dados, processá-los e emitir uma resposta. Isto é feito através de algoritmos ou sequências de instruções lógicas executadas por máquinas (hardware).
A Engenharia de software utiliza métodos, processos e ferramentas para melhorar a qualidade e produtividade dos programas desenvolvidos. Um fruto bem influente da Engenharia de Software foi a notação UML (Unified Modeling Language), utilizada para dar representação visual a diversos conceitos e ideias para resolver problemas com computadores.
A evolução dos modelos de gerenciamento de software, desde o modelo Cascata, dos 1970, até os métodos influenciados pelo Manifesto Ágil, de 2001, seguiu a complexidade de desenvolvimento e organização de equipes, assim como a disponibilidade de máquinas mais potentes e novas linguagens.
Uma atividade de extrema importância no desenvolvimento é o de compreender as entregas e seus limites, normalmente organizados no processo de análise de requisitos, onde estes, os requisitos, podem ser atualizados e até cancelados durante o projeto.
Para que o desenvolvimento de software seja eficiente, é necessário respeitar as fases e seus resultados, obtendo, em cada etapa, artefatos que agregam valor ao produto esperado pelo cliente.
É indispensável que a equipe partipante do projeto seja multidisciplinar, ou seja, que possua analistas de negócio, administradores de bancos de dados, programadores, especialistas em testes, etc... A não separação das responsabilidades pode colocar em risco as entregas, além de criar gargalos técnicos quando múltiplas obrigações são direcionadas as mesmas pessoas.
Vários dos conceitos utilizados em Engenharia de Software foram reunidos em um documento chamado SWEBOK (Software Engineering Body of Knowledge), onde há uma notação própria e diversos processos. Processos são agrupamentos de tarefas com um fim específico e uma metodologia. Devem definir os métodos para tal e as ferramentas úteis de apoio. As ferramentas computacionais que auxiliam a tomada de decisão nos processos são chamadas CASE (Computer-Aided Software Engineering). Alguns exemplos dessas ferramentas:
- IBM Rational Rose
- Microsoft Visio
- Enterprise Architect
- Astah UML
- Ambientes de Desenvolvimento Integrado (IDE)
De forma resumida, há várias etapas em desenvolvimento de software, que, de uma maneira ou outra, seguem:
- Análise
- Arquitetura / Projeto / Design
- Desenvolvimento / Implementação
- Testes
- Implantação
- Manutenção
A análise é a fase onde são esclarecidas as funcionalidades de forma conceitual, sem entrar em detalhes técnicos de implementação, mas levantando dúvidas e potenciais problemas de escopo e funcionamento.
A arquitetura visa organizar a interação entre componentes de forma que as escolhas de solução sejam mais eficientes e com ciclo de manutenção dentro das capacidades da equipe.
O desenvolvimento é a transformação das funcionalidades em código, onde a linguagem de programação já foi escolhida e a ordem de codificação dos módulos é especificada. É neste momento também que se decide pelos sistemas de armazenamento, sistema operacional para rodar o programa, integrações externas, bibliotecas, etc...
Os testes constituem ponto fundamental para entrega de software com qualidade mínima e devem ser planejados com antecedência. Essa etapa, muitas vezes ignorada por pequenas empresas, pode ter um impacto enorme na manutenção depois da entrega, visto que a correção de eventuais bugs aumenta o custo de forma exponencial ao longo do tempo.
Além dos passsos acima, mais habituais, atualmente muito se discute a experiência do usuário (UX = User Experience), que exige uma navegação mais fluída, interativa, inteligente e intuitiva, aumentando ainda mais o grau de complexidade de desenvolvimento.
Algumas características de um software de qualidade são:
- Confiança
- Usabilidade
- Eficiência
- Manutenibilidade
- Portabilidade
Em primeiro lugar, obviamente, estaria a adequação do que foi entregue com as expectativas do cliente, ou seja, as funcionalidades correspondem ao que foi orçado e planejado. É importante que o software seja consistente, ou seja, responda da mesma maneira ao longo do tempo quando a mesma entrada é enviada pelo usuário. A inconsistência está ligada à bugs e problemas de implementação ou implantação, além de testes mal executados ou enviesados.
A usabilidade diz respeito a facilidade com que os usuários podem utilizar o sistema e realizar as tarefas pretendidas sem entraves ou complicações. Um bom design das telas facilita a experiência e reduz a curva de aprendizado, assim como receber feedback dos interessados durante o desenvolvimento ou fase de prototipação reduz o risco da entrega de um programa complexo ou de navegação difícil.
A eficiência é uma medida de quantos recursos o sistema consome e sua velocidade em processar os pedidos dos usuários. Neste quesito, o entedimento sobre análise de algoritmos, estruturas de dados e sistemas operacionais é crucial.
Uma vez entregue, o programa passa para a fase de manutenção. Um software bem planejado e desenhado tem como característica a facilidade em corrigir, atualizar ou reparar suas partes.
A portabilidade é a característica de um software que pode ser executado em diferentes ambientes, plataformas ou sistemas operacionais.
Algumas métricas utilizadas para avaliar a qualidade de um sistema são:
- Tempo médio de recuperação : Avalia o tempo médio que um desenvolvedor leva para descobrir, arrumar e publicar um ajuste no sistema.
- Tempo de ciclo : Mede o tempo de implementação de uma tarefa.
- Taxa de erro : Informa a frequência em que o sistema produziu erros em um determinado ambiente.
- Tempo de entrega : Relaciona o intervalo de tempo entre finalização da tarefa e sua publicação.
- Velocidade do time : Métrica para avaliar a capacidade de entrega do time em uma rodada de trabalho (sprint).
Diferentes equipes recebendo os mesmos requisitos vão planejar e organizar suas atividades utilizando métodos e resultados distintos. Alguns são mais eficientes que outros e, ao longo do tempo, a passagem de conhecimento entre pesquisadores da área fez crescer e promover aqueles que funcionavam melhor.
O modelo mais simples de organizar tarefas tem como base uma lista das atividades pendentes, suas descrições e prazo, não levando em conta aspectos como complexidade, divisão de sub-tarefas entre a equipe, integrações, dependências, etc. Uma hieraquia deve ser discutida para ordenar as tarefas, dando importância para as mais críticas.
A técnica vai se referir ao conjunto de atividades executadas por um time para gerir o desenvolvimento, a implantação e a manutenção do software. O modelo Cascata, criado nos anos 1970, é construído de maneira em que cada etapa seja dependente da anterior, ou seja, de forma sequencial. Sua principal desvantagem é que, em teoria, não há trabalho paralelo de diferentes fases e rodadas de validação com o cliente. Os requisitos são rígidos e o produto final pode, e com frequência o é, diferente do esperado. É necessário um longo período de análise e documentação para prever cenários, tirar dúvidas e levantar o esforço, aumentando em muito o custo do software. Vários documentos são gerados ao longo do processo, como:
- Especificação de Sistema
- Especificação de Requisitos
- Específicação de Projeto
- Listagem de Programas
- Relatório de Testes
No espiral, ou processo evolutivo, planejam-se ciclos com atividades de:
- Comunicação com Cliente
- Planejamento
- Análise de Risco
- Design
- Programação
- Avaliação
onde essas "regiões de tarefas" são repetidas até o término do projeto. Utiliza a análise de risco e mitigação como forma de melhorar cada iteração. Há também o enfoque em prototipação para facilitar os ciclos incrementais.
O modelo em V é uma variação do Cascata, mas que enfatiza os testes ao longo de cada fase. Os tipos de teste são:
- Teste de Unidade
- Teste de Integração
- Teste de Validação
- Teste de Sistema
Onde cada um deles utiliza o documento de especificação produzido em cada fase do processo Cascata.
No paradigma iterativo, temos uma outra atualização do Cascata onde há ciclos de repetição em cada estágio, coletando o feedback de usuários e interessados no projeto para melhorar o entendimento e as entregas parciais.
RAD é um modelo de desenvolvimento rápido e iterativo, com foco em prototipação.
Em modelos que utilizam os princípios ágeis, como o Scrum, o sistema ou produto é quebrado em pequenas partes e desenvolvido em rodadas, chamadas "sprints", que auxiliam na adaptação das mudanças de requisitos, troca de informação entre a equipe, organização do time, entrega de valor nas iterações, colaboração mais efetiva entre os envolvidos e regras de priorização de atividades pendentes. O desenvolvimento contínuo é peça chave para o sucesso do projeto. As equipes são pequenas e se organizam entre Scrum Master, Project Owner e Developers. As atividades pendentes do produto são classificadas como "Product Log". Antes de uma sprint, o time define quais atividades pendentes serão trabalhadas. As escolhidas são chamadas de "Sprint Log" ou "Spring backlog". Após finalizada uma Sprint, a equipe se reune nas cerimônias de Review e Retro, para demonstrar o que foi entregue de valor e discutir o que pode ser melhorado.
O UP (Unified Process), ou Processo Unificado, que deu origem ao RUP criado pela empresa Rational Software Corporation (depois comprado pela IBM), utiliza casos de uso (função do ponto de vista de um ator no sistema) e é utilizado em projetos complexos e grandes equipes, que colhe ideias e sugestões dos envolvidos em iterações que geram um entregável, dando uma direção dinâmica ao produto. Utiliza como base a abordagem de Orientação à Objetos e UML. Pode ser dividida em três perspectivas distintas:
- Dinâmica
- Estática
- Prática
Onde, na pespectiva dinâmica, temos a construção do software através das seguintes fases:
- Iniciação ou Concepção: Define o escopo completo do software, bem como requisitos, prazos e riscos.
- Elaboração: São feitos os documentos de plano de desenvolvimento, especificação técnica e detalhes de arquitetura. Neste momento também se desenvolve um protótipo do projeto.
- Construção: Fase de programação do sistema.
- Transição: Testes, controle de qualidade e implantação.
As atividades principais ou disciplinas são dividas em:
- Modelagem de Negócios
- Requisitos
- Análise e Design
- Implementação
- Testes
- Implantação
- Gerenciamento de Configuração e Mudança
- Gerenciamento de Projeto
- Ambiente
No modelo "estático" as atividades são denominadas workflows (fluxos de trabalho).
A parte "prática" utiliza de ferramentas para melhoria contínua e boas práticas na criação dos processos.
No PERT (Program Evaluation and Review Technique) há o uso de gráficos, cenários e eventos para planejamento dos resultados de cada tarefa do projeto, auxiliando na identificação de falhas e problemas ao longo do tempo. Com ele é possível identificar o tempo mais curto, provável e longo, com base em contingências e problemas no caminho. Os pontos de referência, também chamados de eventos, são nós em um gráfico e se conectam através de linhas aos diferentes trabalhos.
A "Critical Path Technique" foca no caminho mais longo que o projeto pode tomar, com base nas atividades já levantadas. Isso informa os envolvidos quais atividades são prioritárias, removendo barreiras e aumentando a produtividade nos itens que fazem mais diferença primeiro.
A "Critical Chain Technique" deriva de ambas técnicas anteriores mas relaxa alguns requisitos no quesito ordem das tarefas, de forma a alocar mais recursos em avaliar como o time está gastando as horas de desenvolvimento.
A técnica chamada "Extreme Project Management" tem uma abordagem mais aberta quanto aos requisitos formais de escolha das prioridades.
O Kanban é uma metodologia baseada nos princípios ágeis que ajuda a visualizar e controlar as tarefas através de fluxos em um quadro, além de limitar a quantidade de atividades em progresso ao mesmo também. Também incentiva a colaboração, iterações de feedback e respeito aos processos, perfis e responsabilidades do integrantes da equipe.
A família de métodos Crystal tem como foco a capacidade de manobrar prioridades durante fases, chamadas de jogos cooperativos, onde o objetivo é desenvolver as atividades e se preparar para outros elementos secundários futuros. É divido em cores (Yellow, Orange, Red, Maroon e Shappire), cada um voltada para uma quantidade diferentes de integrantes, e letras (C = Confort, D = Discretionary Money ou Baixo Custo, E = Essential Money ou Alto Custo, L = Life ou Risco de Vida) utilizadas para definir a criticidade do produto. Normalmente as entregas ocorrem a cada 60 dias e são colhidos feedbacks de maneira contínua dos clientes e integrantes das equipes. Os ciclos da metodologia são:
- Staging
- Edição e Revisão
- Monitoramento
- Paralelismo e Fluxo
- Inspeções de Usuários
- Workshops para reflexão
- Assuntos locais
- Produtos de trabalho
- Padrões
- Ferramentas
Uma outra técnica moderna e popular para gerenciar o desenvolvimento é a XP ou Extreme Programming. A ideia principal é focar no desenvolvimento de código com qualidade seguindo alguns elementos como:
- Programação em Pares
- Revisão de código
- Testes Unitários
- Simplicidade e Clareza de código
- Requisitos dinâmicos
- YAGNI (You ain't gonna need it) - Programar funcionalidade somente se necessário
Em uma iteração de programação, os princípios fundamentais giram em torno de codificação, testes, ouvir o cliente (listening) e design. Os valores que formam a base da técnica são: simplicidade, comunicação, feedback e coragem. A integração contínua também é uma característica importante da XP, onde os desenvolvedores são estimulados a enviar as alterações que fizeram para o repositório respectivo do projeto diariamente, passando por diversas fases de avaliação da qualidade, segurança e cobertura de testes. Além disso, devem ser definidos testes de aceitação como premissa para entrega de uma funcionalidade.
O Gerenciamento de Configuração de Software (SCM - Software Management Configuration) é um processo utilizado para gerenciar, organizar e controlar alterações em itens de software, por exemplo, documentos, código fonte, imagens, diagramas, etc. O objetivo é implementar as melhores práticas para coordenar e sincronizar alterações nas entidades de software visando melhorias em produtividade e minimização de problemas de versionamento.
Mudanças são muito frequentes durante o desenvolvimento de software e há múltiplos atores participando do projeto, ou seja, diferentes pessoas podem alterar os mesmos arquivos e gerar conflitos de qual versão é a correta ou mais atual. O primeiro passo do SCM é determinar qual o escopo do sistema em desenvolvimento, a "Identificação da Configuração". O CSCI (Computer Software Configuration Item) detalha, em cada alteração:
- O que foi alterado
- O motivo da alteração
- Quando foi alterado
- Por quem foi alterado
Os itens acima são conhecidos como what, why, when and by whom. Eles permitem rastrear, reverter, auditar e monitorar ativos de software de forma organizada e automatizada.
Durante o desenvolvimento de software diversos integrantes de uma equipe podem alterar um mesmo arquivo, gerando novas versões que poderão fazer (ou não) parte da baseline, que é a versão aceita formalmente do item modificado.
Diversos softwares ao longo do tempo fizeram o papel de repositório de código e controle de versão. Atualmente, o sistema distribuído Git é o mais completo e recomendado para gerenciamento de arquivos, além de ser open source, eficiente e estável. Ele administra problemas de concorrência, versionamento, sincronização e resolução de eventuais conflitos entre diferentes versões de um arquivo.
Os participantes no Gerenciamento de Configuração de Software são: Gerente de projeto, Gerente de configuração, Desenvolvedor e Usuário. Todos são responsáveis por garantir que os arquivos estejam no sistema de versionamento, assim como em seguir os processos e resolver eventuais conflitos. Há também o papel do Auditor, responsável por garantir a consistência e integridade das publicações.
No começo do desenvolvimento do software, o documento de planejamento do gerenciamento de configuração de software é produzido com intuito de auxiliar na organização e gestão dos itens do projeto, além de definir a padronização de nomes de arquivos, responsáveis, ferramentas, políticas de versionamento, gestão de mudança e requisitos de armazenamento seguro de dados.
O processo de gestão de mudança deve garantir que uma modificação que será publicada respeita requisitos mínimos de qualidade, consistência e integridade, antes de ser efetivada no repositósio principal.
Caso a nova versão do arquivo seja problemática, os responsáveis podem reverter (rollback) o item para uma versão anterior, utilizando as ferramentas do versionador como meio de avaliar qual modificação causou o problema e que versão anterior pode ser utilizada.
O processo de levantamento de requisitos visa obter as necessidades e os critérios básicos que deverão ser atendidos nas entregas das atividades (parciais ou não). Usualmente os requisitos são documentados em uma reunião com os interessados, clientes externos ou internos à empresa, junto dos analistas de negócio e de sistema, desenvolvedores e equipe de gestão do projeto. As atividades comuns desse processo sao:
- Descrever requisitos
- Analisar requisitos
- Modelagem do sistema
- Especificação de requisitos
- Validação de requisitos
- Gerenciamento de requisitos
As duas primeiras atividades visam transferir e detalhar o conteúdo (ideias, documentos, fluxos, etc.) de uma equipe (cliente) para outra (desenvolvimento). Esse processo é com frequência feito com muitos ruídos, ou seja, as pessoas não discutem o significado de certos pedidos, o que causa falhas no entendimento, propagando o problema na documentação, no desenvolvimento e testes. É de extrema importância que o analista de requisitos ou de sistemas faça boas perguntas para elucidar as necessidades e funcionalidades comunicadas, escrevendo-as de maneira clara e sem ambiguidades. Reuniões, enquetes, grupos de discussão, etc, são meios úteis para comunicação entre as partes.
A atividade de modelagem tem como objetivo a produção de novos documentos para conectar os requisitos com a futura arquitetura do sistema. Os artefatos resultantes podem ser diagramas, fluxos, protótipos e textos que auxiliem os desenvolvedores na tomada de decisão da arquitetura do software e seus prováveis componentes. Algumas ferramentas, como a UML, são muito utilizadas nessa etapa.
A especificação de requisitos é um documento oficial que a equipe de desenvolvimento produz com as informações levantadas em passos anteriores, definindo claramente as funcionalidades, limites do sistema e prioridades. Esse documento é usado no passo posterior, de validação, que exige uma resposta do cliente que os requisitos foram corretamente compreendidos.
A gestão dos requisitos é a atividade que ocorre após a aprovação do escopo do sistema e suas funcionalidades, auxiliando os desenvolvedores na implementação do código e também em eventuais mudanças do que já havia sido levantado. Pode-se dizer que ela continua a ocorrer durante todo o ciclo de vida do projeto.
Os requisitos podem ser classificados em diversos tipos:
- Negócio - Relacionados com regras de negócio sem detalhamento de funcionalidade.
- Cliente - Definem expectativas sobre as funções executadas no sistema com ênfase em sua operação.
- Arquitetura - Restrições ou necessidades específicas para organização da estrutura de componentes do sistema.
- Estrutura - O que deve ser feito com determinadas partes do sistema.
- Comportamento - Define expectativas sobre ações executadas.
- Funcional - Elementos que afetam a experiência do usuário.
- Não funcional - Necessidades que o sistema deve atender que não afetam diretamente as operações executadas pelo usuário (por exemplo, segurança, confiabilidade, regras de backup, etc.).
- Performance - Informam parâmetros mínimos de resposta do sistema com relação às funcionalidades disponíveis.
- Design - Expectativas sobre as decisões de desenho do sistema.
- Alocação - Subdivisão de um requisito de alto-nível para vários em baixo-nível.
Quando utilizamos da UML podemos gerar diferentes diagramas para analisar e detalhar funcionalidades e recursos de um sistema.
Diagramas UML (Unified Modeling Language) são ferramentas gráficas amplamente utilizadas na engenharia de software para modelar, visualizar, especificar e documentar sistemas de software. Essa linguagem de modelagem padronizada oferece um conjunto de diagramas que abrangem diferentes aspectos do desenvolvimento de software, permitindo uma comunicação clara e eficiente entre os membros da equipe de desenvolvimento.
O UML fornece uma variedade de diagramas que abordam diferentes perspectivas e aspectos do sistema. Alguns dos diagramas UML mais comuns incluem:
-
Diagrama de Caso de Uso (Use Case Diagram): Esse diagrama é usado para identificar, modelar e descrever os requisitos funcionais do sistema, mostrando as interações entre atores (usuários ou sistemas externos) e os casos de uso do sistema.
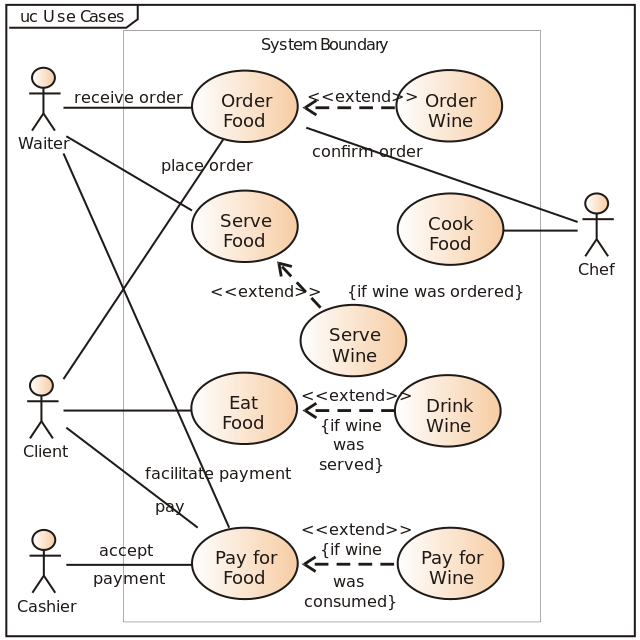
Diagrama de casos de uso. Fonte: Wikipédia -
Diagrama de Classes (Class Diagram): O diagrama de classes é usado para representar as classes do sistema, seus atributos, métodos e relacionamentos. Ele descreve a estrutura estática do sistema, mostrando as classes e como elas estão relacionadas umas com as outras.

Diagrama de classe. Fonte: Medium - Salma Os símbolos utilizados no diagrama de classe, para relação entre elas, são:
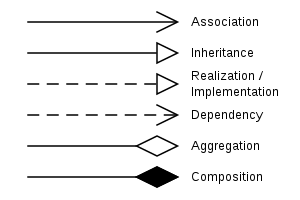
Fonte: WikiWand -
Diagrama de Sequência (Sequence Diagram): O diagrama de sequência ilustra a interação entre objetos em uma determinada sequência de eventos. Ele mostra a troca de mensagens entre os objetos ao longo do tempo, permitindo visualizar o fluxo de execução em um cenário específico.
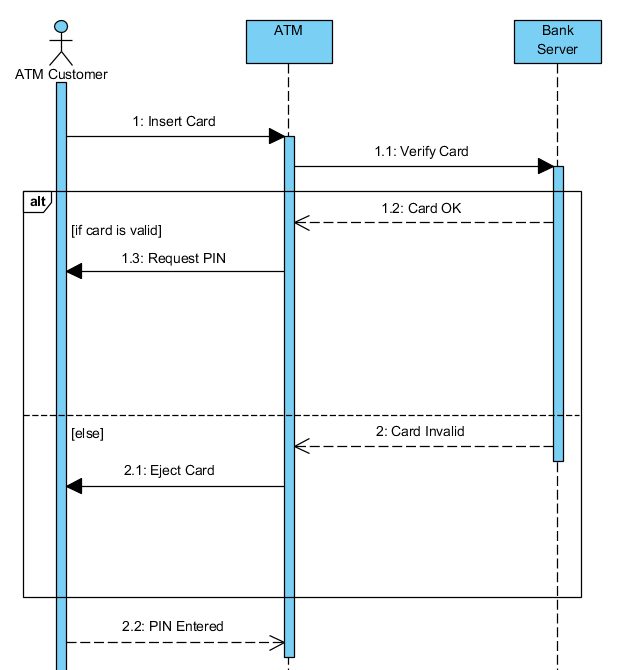
Diagrama de sequência. Fonte: Stack Overflow - Usuário Scaramouche -
Diagrama de Atividades (Activity Diagram): Esse diagrama é usado para modelar o fluxo de trabalho de um processo ou algoritmo. Ele mostra as atividades do sistema, as decisões tomadas e as transições entre as atividades.
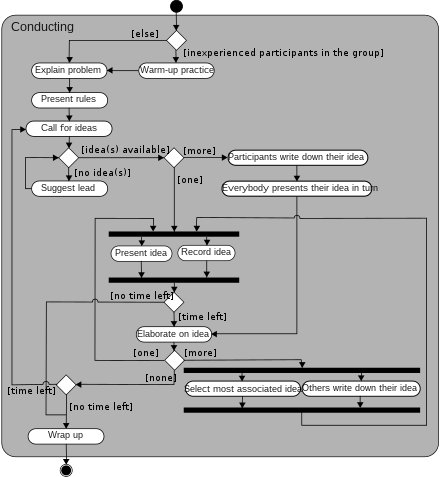
Diagrama de atividade. Fonte: Wikipédia -
Diagrama de Componentes (Component Diagram): O diagrama de componentes descreve a estrutura de componentes de um sistema, incluindo suas dependências e interfaces. Ele mostra como os diferentes componentes são agrupados e como se comunicam entre si.

Diagrama de componentes. Fonte: UML Diagrams Org -
Diagrama de Estados (State Diagram): Esse diagrama é usado para modelar o comportamento de um objeto em diferentes estados e as transições entre eles.

Diagrama de estados. Fonte: Draw IO
Garantir a qualidade do software é testá-lo sistematicamente obtendo resultados consistentes dentro de uma métrica pré-definida. Diversos processos podem ser utilizados para obter um padrão de qualidade alto, seja através de certificações (CMMI por exemplo) para melhoria contínua, exigência de cobertura mínima dos testes ou modelos de treinamento e validação do código produzido (CI / CD).
O processo de gestão de qualidade de software pode ser dividido em três tipos:
- Garantia de Qualidade (QA = Quality Assurance) - Definir os requisitos mínimos de entrega do produto e níveis de confiança.
- Planejamento de Qualidade - Organizar os diferentes tipos de testes, incluindo: navegação, performance, escalabilidade, etc, e também políticas de risco.
- Controle de Qualidade - Executar os testes e revisar se resultados estão de acordo com o esperado.
Alguns processos auxiliam na organização dos requisitos através de comportamentos esperados e seus respectivos testes, antes mesmo de começar a produzir código. A BDD (Behavior Driven Development = Desenvolvimento Orientado por Comportamento) busca a integração de diferentes áreas (desenvolvimento, qualidade e negócios) para compor a gestão dos requisitos com fins de avaliar o comportamento das funcionalidades. Essa técnica tem como premissa a criação dos testes, em conjunto, pelo PO (Product Owner), QA (Quality Analyst) e os Desenvolvedores. Cada cenário de teste no software é dividido em três partes:
- Given - Estado inicial e pré-condições
- When - Quando algo acontecer (por usuário ou sistema)
- Then - Resultado esperado
Pode-se dizer que o BDD é uma evolução do TDD (Test Driven Development = Desenvolvimento Orientado por Testes) onde, no último, os desenvolvedores escrevem casos de teste, programam o código e vão refinando o que foi desenvolvido através da validação e adesão aos cenários de testes. Esse é o ciclo chamado Red, Green, Refactor.
Normalmente se utiliza o idioma nativo da equipe para escrever os testes, acompanhada da Linguagem Ubíqua, que representa a estrutura linguística do domínio do projeto, contendo jargões e termos técnicos que devem orientar entendimentos de negócios. O processo do BBD ainda pode ser subdividido em três fases distintas e complementares:
- Definição
- Formalização
- Entrega
Verificação, validação e teste são três aspectos críticos da engenharia de software essenciais para garantir a qualidade e a confiabilidade dos produtos de software. Embora frequentemente usados de forma intercambiável, esses três termos referem-se a processos distintos que são usados ao longo do ciclo de vida do desenvolvimento de software.
A verificação refere-se ao processo de garantir que os produtos de software atendam aos requisitos especificados e às especificações de projeto. Isso envolve revisar os documentos de código e design para garantir que eles atendam à funcionalidade desejada e às metas de desempenho. A verificação pode ser realizada manualmente ou por meio de ferramentas e processos automatizados, como revisões de código e ferramentas de análise estática.
A validação, por outro lado, refere-se ao processo de garantir que os produtos de software atendam às necessidades dos usuários e partes interessadas. Isso envolve testar o software em cenários do mundo real para garantir que ele funcione conforme o esperado e atenda à experiência do usuário desejada. A validação normalmente envolve testes de aceitação do usuário e outras formas de teste que simulam cenários do mundo real.
O teste, o aspecto final da garantia de qualidade do software, refere-se ao processo de execução do código para encontrar erros ou bugs. O teste pode ser realizado em vários estágios do ciclo de vida de desenvolvimento de software, incluindo teste de unidade, teste de integração e teste de sistema. Ferramentas de teste automatizadas podem ser usadas para agilizar o processo de teste e garantir que os produtos de software sejam completamente testados antes do lançamento.
Embora verificação, validação e teste sejam processos distintos, todos são essenciais para garantir a qualidade e a confiabilidade dos produtos de software. Ao combinar esses processos ao longo do ciclo de vida de desenvolvimento de software, os desenvolvedores podem identificar e corrigir erros e bugs no início do processo de desenvolvimento, garantindo que os produtos de software atendam às metas desejadas de funcionalidade, desempenho e experiência do usuário.
Além de sua função na garantia da qualidade do software, a verificação, a validação e o teste também são essenciais para a conformidade regulamentar e o gerenciamento de riscos. Ao garantir que os produtos de software atendam aos regulamentos e padrões necessários, as organizações podem evitar responsabilidades legais e financeiras, ao mesmo tempo em que reduzem o risco de falhas de software ou violações de segurança.
A manutenção do código é um aspecto essencial da engenharia de software que envolve atualização, aprimoramento e correção de problemas no código existente para garantir que ele continue funcionando conforme o esperado. O código de software é uma entidade viva que precisa ser mantida e atualizada ao longo do tempo para atender aos requisitos em constante mudança e solucionar bugs ou erros que surgem durante seu uso.
A manutenção do código pode envolver uma série de atividades, incluindo corrigir bugs, melhorar o desempenho, adicionar novos recursos, atualizar a documentação e garantir que o código seja compatível com as plataformas de hardware e software mais recentes. A manutenção eficaz do código é fundamental para o sucesso de qualquer projeto de software, pois garante que o código permaneça relevante e utilizável ao longo do tempo.
Um dos aspectos mais importantes da manutenção do código é garantir que o código permaneça legível e compreensível. Isso envolve seguir as práticas recomendadas para organização de código, comentar o código para explicar sua finalidade e funcionalidade e usar convenções de nomenclatura consistentes para variáveis, funções e classes. Mantendo o código bem organizado e de fácil leitura, fica muito mais fácil identificar e corrigir problemas que possam surgir.
Outro aspecto importante da manutenção do código é o teste. Testes regulares garantem que quaisquer alterações feitas no código não introduzam novos problemas ou causem consequências indesejadas. Isso pode envolver testes de unidade, testes de integração e testes de desempenho para garantir que o código funcione conforme pretendido e atenda aos padrões de qualidade desejados.
Além de testar, a manutenção do código também envolve manter-se atualizado com as últimas tendências e tecnologias de desenvolvimento de software. Isso inclui revisar e atualizar regularmente o código para incorporar novas práticas recomendadas, estruturas e bibliotecas. Ao se manter atualizado com os desenvolvimentos mais recentes em engenharia de software, fica muito mais fácil manter o código e garantir que ele permaneça relevante e útil ao longo do tempo.
A documentação garante o entendimento mínimo entre as expectativas do cliente e o que será desenvolvido pela equipe, removendo eventuais conflitos de compreensão e definindo claramente o que está fora dos limites. É importante que a equipe entenda o papel da escrita no projeto, visto que a falta de referências implica em dificuldades de resolução de atividades, funcionalidades incorretas, erros em regras de negócio e aumento exorbitante nos custos.
Uma boa documentação pode ajudar a garantir que o sistema atenda ao objetivo pretendido, além de facilitar sua manutenção e atualização ao longo do tempo. Também pode ser útil para novos membros da equipe que estão ingressando no projeto ou para partes interessadas externas que precisam entender como o sistema funciona.
Existem vários tipos de documentação que podem ser criados durante o processo de desenvolvimento de software. Por exemplo, a documentação de requisitos descreve os requisitos funcionais e não funcionais do sistema. A documentação do projeto descreve a arquitetura, os módulos e os componentes do sistema. A documentação de teste descreve os vários testes que serão executados para garantir que o sistema atenda aos seus requisitos. A documentação do usuário fornece informações sobre como usar o sistema.
Além desses tipos específicos de documentação, também existem alguns princípios que devem ser seguidos ao criar qualquer tipo de documentação de software. A documentação deve ser clara, concisa e precisa. Ele também deve ser organizado de maneira lógica e deve usar terminologia consistente. Além disso, a documentação deve ser mantida atualizada durante todo o processo de desenvolvimento de software, à medida que as alterações são feitas no sistema.
A criação de uma boa documentação pode ser demorada e exigir recursos adicionais, mas pode ser um investimento valioso a longo prazo. A documentação adequada pode ajudar a garantir que o sistema de software seja bem compreendido por todas as partes interessadas, reduzindo o risco de falhas de comunicação ou mal-entendidos. Também pode facilitar a manutenção e atualização do sistema ao longo do tempo, reduzindo custos e melhorando a eficiência.
Os padrões de design são soluções reutilizáveis para problemas comuns de design de software que foram experimentados e testados ao longo do tempo. Eles são considerados as melhores práticas em engenharia de software e ajudam a melhorar a qualidade, capacidade de manutenção e escalabilidade dos sistemas de software.
Um padrão de design comum em C# é o padrão Singleton, que garante que apenas uma instância de uma classe seja criada e fornece acesso global a essa instância. Aqui está um exemplo do padrão Singleton em C#:
public class Singleton {
private static Singleton instance;
private static object lockObject = new object();
private Singleton() {
// private constructor to prevent instantiation from outside the class
}
public static Singleton GetInstance() {
if (instance == null) {
lock(lockObject) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
public void SayHello() {
Console.WriteLine("Hello from Singleton!");
}
}
Neste exemplo, a classe Singleton possui um construtor privado, que impede que o código externo crie novas instâncias da classe. Em vez disso, é fornecido um método estático público chamado "GetInstance", que retorna a única instância da classe. O método usa bloqueio verificado duas vezes para garantir que apenas uma instância seja criada, mesmo em um ambiente multithread.
Outro padrão de design comum em C# é o padrão Factory, que fornece uma interface para criar objetos sem especificar suas classes concretas. Aqui está um exemplo do padrão Factory em C#:
public interface IAnimal {
void Speak();
}
public class Dog : IAnimal {
public void Speak() {
Console.WriteLine("Woof!");
}
}
public class Cat : IAnimal {
public void Speak() {
Console.WriteLine("Meow!");
}
}
public class AnimalFactory {
public static IAnimal CreateAnimal(string type) {
switch(type) {
case "dog":
return new Dog();
case "cat":
return new Cat();
default:
throw new ArgumentException("Invalid animal type");
}
}
}
Neste exemplo, a classe AnimalFactory fornece um método estático chamado "CreateAnimal", que recebe um argumento de string que representa o tipo de animal a ser criado. Dependendo do argumento, o método retorna uma instância da classe concreta apropriada, Dog ou Cat. Isso permite que os clientes da fábrica criem novos animais sem precisar conhecer os detalhes específicos de implementação de cada classe de animal.
Aqui está uma lista de alguns dos padrões de projeto mais comumente usados:
1. Padrões de Criação:
- Singleton: Garante que apenas uma instância de uma classe seja criada e forneça acesso global a essa instância.
- Factory Method: Fornece uma interface para criar objetos sem especificar suas classes concretas.
- Abstract Factory: Fornece uma interface para criar famílias de objetos relacionados sem especificar suas classes concretas.
- Construtor: Separa a construção de um objeto complexo de sua representação, permitindo que um mesmo processo de construção crie diferentes representações.
- Protótipo: Permite a criação de novos objetos por meio da clonagem de objetos existentes.
2. Padrões Estruturais:
- Adaptador: permite que objetos incompatíveis trabalhem juntos criando um objeto intermediário que faz a tradução entre eles.
- Bridge: Separa a interface de um objeto de sua implementação, permitindo que variem de forma independente.
- Composto: Compõe objetos em estruturas de árvore para representar hierarquias parte-todo.
- Decorator: Acrescenta responsabilidades a um objeto dinamicamente sem modificar sua classe original.
- Fachada: Fornece uma interface simplificada para um sistema complexo de classes.
- Flyweight: Compartilha objetos para reduzir o uso de memória quando muitas instâncias do mesmo objeto são necessárias.
- Proxy: fornece um espaço reservado ou substituto para outro objeto para controlar o acesso a ele.
3. Padrões Comportamentais:
- Cadeia de Responsabilidade: Permite que vários objetos tratem uma requisição, passando-a por uma cadeia até que um objeto a trate.
- Comando: Encapsula uma requisição como um objeto, permitindo que ela seja parametrizada, enfileirada ou logada.
- Intérprete: define a gramática de uma língua e a utiliza para interpretar expressões escritas nessa língua.
- Iterator: fornece uma maneira de acessar os elementos de um objeto agregado sequencialmente sem expor sua representação subjacente.
- Mediador: Define um objeto que encapsula como um conjunto de objetos interage, permitindo que eles trabalhem juntos sem serem fortemente acoplados.
- Memento: Permite que um objeto capture e restaure seu estado interno sem violar o encapsulamento.
- Observer: Define uma dependência um-para-muitos entre objetos de forma que quando um objeto muda de estado, todos os seus dependentes são notificados e atualizados automaticamente.
- Estado: permite que um objeto altere seu comportamento quando seu estado interno muda, criando um objeto separado para cada estado possível e delegando requisições ao objeto apropriado.
- Estratégia: define uma família de algoritmos, encapsula cada um deles e os torna intercambiáveis em tempo de execução.
- Template Method: Define o esqueleto de um algoritmo em uma classe base, permitindo que suas subclasses redefinam determinados passos sem alterar a estrutura do algoritmo.
- Visitante: Separa um algoritmo de uma estrutura de objeto movendo o algoritmo para um objeto separado que pode visitar os elementos da estrutura de forma independente.
Esses padrões de projeto são apenas alguns dos muitos padrões existentes na engenharia de software. Ao usar esses padrões, os desenvolvedores podem criar sistemas de software mais fáceis de manter, estender e modificar ao longo do tempo.
A reutilização de código é um princípio fundamental da engenharia de software que envolve o uso de código existente para construir novos aplicativos de software. Em vez de começar do zero para cada novo projeto, os desenvolvedores podem aproveitar as bibliotecas de código, estruturas e módulos existentes para acelerar o desenvolvimento e melhorar a qualidade do software.
Uma maneira comum de obter a reutilização de código é por meio do uso de funções e bibliotecas. Na linguagem de programação C, as funções permitem que os desenvolvedores encapsulem um conjunto de instruções em um bloco reutilizável de código que pode ser chamado de vários lugares dentro de um programa. As bibliotecas, por outro lado, são coleções de funções e estruturas de dados projetadas para serem reutilizadas em vários projetos.
Por exemplo, vamos considerar um programa simples que calcula a área de um retângulo. Podemos definir uma função chamada "calculate_area" que recebe o comprimento e a largura do retângulo como argumentos e retorna a área calculada:
#include <stdio.h>
int calculate_area(int length, int width) {
int area = length * width;
return area;
}
int main() {
int length = 10;
int width = 5;
int area = calculate_area(length, width);
printf("The area of the rectangle is %d", area);
return 0;
}
Neste exemplo, a função "calculate_area" encapsula a lógica para calcular a área de um retângulo. Esta função pode ser reutilizada em outras partes do programa ou em outros programas.
Outra maneira de obter a reutilização de código em C é por meio do uso de bibliotecas. Por exemplo, a biblioteca C padrão fornece uma ampla variedade de funções que podem ser usadas em programas C. Essas funções incluem operações de entrada/saída, funções de manipulação de strings e funções matemáticas, entre outras.
Para usar uma biblioteca em C, os desenvolvedores precisam incluir o arquivo de cabeçalho apropriado em seu código e vincular o código à biblioteca durante a compilação. Por exemplo, para usar a função "sin" da biblioteca matemática, o seguinte código pode ser escrito:
#include <stdio.h>
#include <math.h>
int main() {
double x = 3.14159;
double y = sin(x);
printf("The sine of %f is %f", x, y);
return 0;
}
Neste exemplo, o arquivo de cabeçalho "math.h" é incluído para permitir o uso da função "sin" da biblioteca matemática. O programa resultante calcula o seno de 3,14159 e imprime o resultado no console.
O processo de reconstruir um software sem dispor do código fonte é chamado de Engenharia Reversa. Há diversas técnicas e fins envolvidos, sejam lícitas ou não, sendo que o processo básico envolve:
- Análise
- Desenho de recuperação
- Reconstrução
Algumas das principais técnicas que podem ser usadas na engenharia reversa de um sistema sem código-fonte incluem:
- Depuração: A depuração envolve a análise do comportamento de um sistema em execução para entender como ele funciona e identificar quaisquer erros ou problemas que possam estar presentes.
- Descompilação: A descompilação envolve o uso de ferramentas para converter o código da máquina de volta em sua linguagem de programação original, permitindo que os desenvolvedores entendam como o sistema funciona e modifiquem-no conforme necessário.
- Desmontagem: A desmontagem envolve a quebra do código de máquina de um sistema em suas instruções de linguagem de montagem individuais, permitindo que os desenvolvedores entendam como o sistema funciona em um nível baixo.
Desmontagem (Disassembly) é uma técnica usada na engenharia reversa que envolve a quebra do código de máquina de um programa de software em suas instruções de linguagem de montagem individuais. A linguagem Assembly é uma linguagem de programação de baixo nível que usa mnemônicos para representar instruções de máquina individuais, tornando mais fácil para os desenvolvedores entender e modificar o código.
Quando um programa de software é compilado, ele é convertido de uma linguagem de programação de nível superior, como C++ ou Java, em código de máquina que pode ser executado diretamente pelo processador do computador. A desmontagem envolve a análise desse código de máquina e sua conversão novamente em linguagem assembly, permitindo que os desenvolvedores entendam como o programa funciona em um nível baixo.
Aqui está um exemplo de como a desmontagem funciona, usando a linguagem assembly x86:
Digamos que temos um programa C simples que soma dois números:
#include <stdio.h>
int main() {
int x = 5;
int y = 10;
int z = x + y;
printf("The sum of %d and %d is %d\n", x, y, z);
return 0;
}
Usando um desmontador, podemos converter o código de máquina em instruções de linguagem assembly. Aqui está o código desmontado resultante:
push rbp
mov rbp,rsp
sub rsp,0x10
mov DWORD PTR [rbp-0x4],0x5
mov DWORD PTR [rbp-0x8],0xa
mov eax,DWORD PTR [rbp-0x4]
add eax,DWORD PTR [rbp-0x8]
mov DWORD PTR [rbp-0xc],eax
mov eax,DWORD PTR [rbp-0x4]
mov esi,eax
mov eax,DWORD PTR [rbp-0x8]
mov edi,eax
mov eax,DWORD PTR [rbp-0xc]
mov edx,eax
mov edi,OFFSET FLAT:.LC0
mov eax,0x0
call printf
mov eax,0x0
leave
ret
Este código assembly nos mostra as instruções individuais que o programa está executando. Por exemplo, podemos ver que o programa está carregando os valores de x e y nos registradores, somando-os e armazenando o resultado em uma nova variável z. Também podemos ver o código que imprime o resultado usando a função printf.
A técnica da Muralha da China é uma metodologia bem conhecida usada no campo da segurança de computadores para evitar conflitos de interesse e garantir que informações confidenciais sejam protegidas contra acesso ou divulgação não autorizados. Essa técnica pode ser usada para impedir a engenharia reversa de software proprietário ou para proteger a propriedade intelectual dos fornecedores de software.
Para evitar a engenharia reversa, os fornecedores de software podem usar a técnica da muralha chinesa para compartimentalizar seu software em diferentes áreas ou módulos funcionais. Cada módulo é então atribuído a uma equipe de desenvolvimento diferente, com acesso restrito apenas aos indivíduos que precisam dele para concluir suas tarefas. As equipes são então isoladas umas das outras para evitar o compartilhamento de informações e para garantir que cada equipe esteja trabalhando de forma independente.
A técnica da muralha da China também pode ser usada para proteger a propriedade intelectual dos fornecedores de software, impedindo o acesso não autorizado ao código-fonte ou outras informações proprietárias. Ao compartimentalizar o software em diferentes módulos, o fornecedor pode limitar o acesso a informações confidenciais apenas aos indivíduos que têm uma necessidade legítima delas.
Embora a técnica da muralha da China possa ser eficaz na prevenção da engenharia reversa e na proteção da propriedade intelectual, ela não é infalível. Técnicas avançadas de engenharia reversa podem ser usadas para contornar essas barreiras, e a técnica da muralha da China também pode dificultar a execução de manutenção ou atualizações de software.
A técnica de sala limpa (Clean Room Technique) é uma metodologia usada na engenharia reversa para analisar e recriar software sem infringir os direitos de propriedade intelectual. Essa técnica é útil para fornecedores de software que desejam criar software compatível ou para indivíduos que desejam entender a funcionalidade de um produto de software proprietário.
A técnica envolve a criação de duas equipes: uma equipe que analisa o software e cria uma especificação funcional e outra equipe que recria o software com base nessa especificação. A equipe que analisa o software o faz examinando-o de fora, sem acesso ao código-fonte ou conhecimento do funcionamento interno do software. Eles então criam uma especificação funcional que descreve o comportamento do software, incluindo suas entradas, saídas e lógica.
A equipe que recria o software usa a especificação funcional para desenvolver uma nova versão do software. Eles fazem isso sem qualquer referência ao código-fonte original ou qualquer conhecimento do funcionamento interno do software original. Essa equipe deve garantir que o novo software se comporte da mesma forma que o software original, com base na especificação funcional.
A técnica de sala limpa é uma maneira eficaz de analisar e recriar software sem infringir os direitos de propriedade intelectual. Ao separar as equipes que analisam e recriam o software, ele garante que os indivíduos que recriam o software o façam sem nenhum conhecimento do código-fonte original ou de qualquer outra informação proprietária. Essa técnica também ajuda a garantir que o software recriado não seja uma cópia do software original, mas sim uma nova versão baseada na especificação funcional.
No entanto, a técnica pode ser demorada e cara, pois requer a criação de duas equipes separadas e a análise e recriação do software com base na especificação funcional. Além disso, o software recriado pode não ser idêntico ao software original pois é baseado na especificação funcional e não no código-fonte real.
Reengenharia refere-se ao processo de modificação, redesenho ou refatoração de sistemas de software existentes para melhorar sua qualidade, desempenho ou funcionalidade. A reengenharia é normalmente realizada quando um sistema de software se torna desatualizado, difícil de manter ou não atende mais às necessidades de seus usuários.
A reengenharia pode envolver alterações na arquitetura do software, redesenhar as interfaces do usuário ou atualizar o código para usar tecnologias ou linguagens de programação mais recentes.
Pode ser um processo complexo e demorado que normalmente requer uma compreensão completa do sistema de software existente e suas dependências. Pode envolver engenharia reversa, que é o processo de análise e compreensão do código existente e da arquitetura do sistema.
A reengenharia pode ser desencadeada por uma variedade de fatores, incluindo mudanças nos requisitos de negócios, atualizações de tecnologia ou a necessidade de melhorar o desempenho ou a escalabilidade do sistema. Muitas vezes, é realizado como parte de um projeto de desenvolvimento de software maior, como uma atualização de software ou migração para uma nova plataforma.
Existem várias técnicas comumente usadas na reengenharia de sistemas de software. Essas técnicas ajudam a identificar áreas do sistema que precisam de melhorias e a planejar e implementar mudanças no sistema de maneira sistemática e eficaz. Algumas das principais técnicas usadas na reengenharia incluem:
- Reestruturação: envolve fazer alterações na estrutura do sistema para melhorar sua capacidade de manutenção, extensibilidade e reutilização. Isso pode envolver a reorganização do código, a separação dos interesses em diferentes módulos ou a refatoração do código para melhorar sua legibilidade e reduzir sua complexidade.
- Engenharia avançada: envolve o uso das informações coletadas por meio de engenharia reversa e reestruturação para criar uma nova versão do sistema. Isso pode envolver a implementação de novos recursos, atualizar o sistema para usar tecnologias ou linguagens de programação mais recentes ou melhorar o desempenho do sistema.
- Migração: envolve mover o sistema existente para uma nova plataforma ou arquitetura. Isso pode envolver a atualização do sistema para usar versões mais recentes de sistemas operacionais ou middleware ou mover o sistema para um ambiente baseado em nuvem.
- Reutilização: envolve a identificação de componentes do sistema existente que podem ser reutilizados em outros sistemas. Isso pode ajudar a reduzir o tempo e os custos de desenvolvimento, bem como melhorar a qualidade do sistema que está sendo desenvolvido.
- Teste: Envolve testar o sistema modificado ou reprojetado para garantir que ele atenda aos requisitos das partes interessadas e que esteja livre de erros e defeitos.
A inteligência artificial (IA) pode ser usada para auxiliar na migração de código, automatizando alguns dos aspectos mais rotineiros ou repetitivos do processo, permitindo que os desenvolvedores se concentrem em tarefas de nível superior e reduzindo o risco de erros ou inconsistências.
Uma maneira pela qual a IA pode ajudar na migração de código é identificando automaticamente padrões de código e sugerindo implementações alternativas. Por exemplo, se um desenvolvedor está migrando um aplicativo Java para uma plataforma .NET, uma ferramenta AI pode analisar o código Java e sugerir um código .NET equivalente que alcance a mesma funcionalidade. Isso pode economizar uma quantidade significativa de tempo e esforço, pois o desenvolvedor não precisa traduzir manualmente cada linha de código e reduz o risco de introduzir erros ou inconsistências.
Outra maneira pela qual a IA pode ajudar na migração de código é refatorando automaticamente o código para cumprir os padrões de codificação e as melhores práticas da plataforma de destino. Por exemplo, se a plataforma de destino exigir que todos os nomes de variáveis estejam em maiúsculas e minúsculas, uma ferramenta de IA pode renomear automaticamente as variáveis no código-fonte para obedecer a esse padrão. Isso pode melhorar a qualidade do código e reduzir a quantidade de esforço manual necessário para colocar o código no padrão exigido.
A IA também pode ser usada para auxiliar no teste e validação durante a migração de código. Por exemplo, uma ferramenta de IA pode gerar automaticamente casos de teste com base no código original e, em seguida, executar esses casos de teste no código migrado para garantir que ele se comporte corretamente. Isso pode reduzir o risco de introdução de bugs ou regressões durante o processo de migração e fornecer confiança de que o código migrado é funcionalmente equivalente ao original.
Um Ambiente de Desenvolvimento Integrado (IDE) é um aplicativo de software que fornece aos desenvolvedores um conjunto abrangente de ferramentas para escrever e testar código. É um componente crítico da engenharia de software moderna, pois agiliza o processo de codificação, aumenta a eficiência e reduz os erros.
Os IDEs geralmente incluem um editor de texto com recursos avançados, como realce de sintaxe, preenchimento automático e recursos de depuração. Eles também podem incluir compiladores, depuradores e outras ferramentas integradas para ajudar os desenvolvedores a escrever, testar e depurar o código.
Uma das principais vantagens de usar um IDE é a capacidade de escrever código em um único ambiente integrado. Isso significa que os desenvolvedores podem escrever, testar e depurar seu código sem precisar alternar entre várias ferramentas ou aplicativos. Isso pode economizar uma quantidade significativa de tempo e melhorar a produtividade geral.
Outra vantagem de usar um IDE é a capacidade de personalizar o ambiente para atender às preferências e fluxos de trabalho individuais. Por exemplo, os desenvolvedores podem adicionar plug-ins ou extensões para oferecer suporte a diferentes linguagens ou estruturas de programação ou configurar atalhos de teclado e outras configurações para otimizar seu fluxo de trabalho.
No geral, os IDEs são uma ferramenta essencial para a engenharia de software moderna. Eles ajudam os desenvolvedores a escrever códigos de alta qualidade com mais eficiência, reduzir erros e aumentar a produtividade. À medida que a tecnologia continua a evoluir, podemos esperar que os IDEs se tornem ainda mais sofisticados e poderosos, ajudando os desenvolvedores a ultrapassar os limites do que é possível na engenharia de software.
Existem muitos IDEs diferentes disponíveis para desenvolvedores de software, cada um com seu próprio conjunto exclusivo de recursos e capacidades. Aqui estão alguns exemplos de IDEs populares e suas principais características:
- Visual Studio: Desenvolvido pela Microsoft, o Visual Studio é um IDE abrangente que oferece suporte a várias linguagens e estruturas de programação diferentes, incluindo .NET, C++, JavaScript e Python. Ele inclui um rico conjunto de ferramentas para depuração, teste e criação de perfil de código, bem como suporte integrado para desenvolvimento baseado em nuvem.
- Eclipse: Eclipse é um IDE de software livre amplamente utilizado na comunidade de desenvolvimento Java. Ele inclui um poderoso editor de texto com recursos avançados, como preenchimento automático e realce de código, além de suporte para uma ampla variedade de linguagens e estruturas de programação. Ele também inclui ferramentas para depuração e teste de código e oferece suporte ao desenvolvimento colaborativo por meio de plug-ins como o Git.
- Xcode: Desenvolvido pela Apple, o Xcode é um IDE projetado especificamente para desenvolvimento em macOS e iOS. Inclui um editor com suporte para Swift e Objective-C, bem como ferramentas para depuração, teste e criação de perfil de código. Ele também inclui uma variedade de ferramentas de desenvolvimento integradas, como o Interface Builder para projetar interfaces de usuário.
- IntelliJ IDEA: IntelliJ IDEA é um IDE popular entre os desenvolvedores Java. Inclui um editor com ferramentas avançadas de análise e refatoração de código, além de suporte para outras linguagens de programação como Python e JavaScript. Ele também inclui ferramentas para depuração, teste e criação de perfil de código e oferece suporte à integração com ferramentas de compilação populares, como Maven e Gradle.
- PyCharm: PyCharm é um IDE projetado especificamente para desenvolvimento em Python. Ele inclui um rico conjunto de ferramentas para escrever, testar e depurar código Python, bem como suporte para estruturas Python populares como Django e Flask. Ele também inclui suporte para outras linguagens de programação, como JavaScript e TypeScript, tornando-o uma ferramenta versátil para desenvolvimento full-stack.
- VSCode (Visual Studio Code): O Visual Studio Code é um editor de código-fonte desenvolvido pela Microsoft para Windows, Linux e macOS. Ele inclui suporte para depuração, controle de versionamento Git incorporado, realce de sintaxe, complementação inteligente de código, snippets e refatoração de código (Texto extraído da Wikipédia).
Aproveitando o poder da IA, os IDEs podem se tornar ainda mais produtivos e eficientes, permitindo que os desenvolvedores escrevam códigos melhores em menos tempo.
Uma maneira pela qual a IA pode ser integrada aos IDEs é por meio do uso de análise de código e ferramentas de previsão. Essas ferramentas usam algoritmos de aprendizado de máquina para analisar o código existente e prever como ele se comportará em diferentes cenários. Isso pode ajudar os desenvolvedores a identificar possíveis erros ou problemas de desempenho antes que eles ocorram e sugerir melhorias ou otimizações que podem tornar o código mais eficiente.
Outra maneira pela qual a IA pode ser integrada aos IDEs é por meio do uso de ferramentas de conclusão e sugestão de código. Essas ferramentas usam processamento de linguagem natural e algoritmos de aprendizado de máquina para sugerir trechos de código e sintaxe à medida que os desenvolvedores digitam, economizando tempo e reduzindo erros. Por exemplo, um IDE com IA pode sugerir a sintaxe correta para uma chamada de função ou sugerir um padrão de código comumente usado com base no contexto do código que está sendo escrito.
A IA também pode ser usada para melhorar o processo de teste e depuração nos IDEs. Ao analisar o comportamento do código e identificar padrões, a IA pode ajudar os desenvolvedores a identificar a causa raiz dos erros e sugerir possíveis correções. Isso pode economizar tempo dos desenvolvedores e reduzir o tempo total de lançamento no mercado de produtos de software.
Referências:
- Engenharia de Software - Univesp
- Engenharia de Software - Kechi Hirama
- Desenvolvimento Orientado Por Comportamento - Dev Media
- Software Configuration Management in Software Engineering