Prova PosComp 2022
Clique em cada item para ver as perguntas e respostas.

Primeiro podemos calcular a expressão $A-2I$, onde $I$ é a matriz 2x2 identidade, dada por:
$$ \begin{pmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \\ \end{pmatrix} $$que multiplicada por 2, fica:
$$ \begin{pmatrix} 2 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 2 \\ \end{pmatrix} $$Então, resolvemos:
$$ \begin{pmatrix} 1 & -2 & 1 \\ 3 & -2 & -1 \\ 4 & -1 & 2 \\ \end{pmatrix} - \begin{pmatrix} 2 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 2 \\ \end{pmatrix} = \begin{pmatrix} -1 & -2 & 1 \\ 3 & -4 & -1 \\ 4 & -1 & 0 \\ \end{pmatrix} $$Agora calculamos a exponenciação dessa nova matriz:
$$ \begin{pmatrix} -1 & -2 & 1 \\ 3 & 0 & -1 \\ 4 & -1 & 0 \\ \end{pmatrix} \cdot \begin{pmatrix} -1 & -2 & 1 \\ 3 & 0 & -1 \\ 4 & -1 & 0 \\ \end{pmatrix} = \begin{pmatrix} -1 & 9 & 1 \\ -19 & 11 & 7 \\ -7 & -4 & 5 \\ \end{pmatrix} $$Resposta: b

Queremos escrever o vetor $w=(0,2,a)$ como uma combinação linear dos vetores $u=(4,0,5)$ e $v=(2,a,3)$, ou seja:
$$ w=\alpha u + \beta v \\ (0,2,a)=\alpha (4,0,5)+\beta (2,a,3) $$De forma que temos um sistema com 3 equações e 3 incógnitas:
$$ 4\alpha + 2\beta = 0 \\ 0\alpha + a\beta = 2 \\ 5\alpha + 3\beta = a \\ $$De onde tiramos as relações:
$$ 2\alpha=-\beta \\ a\beta=2 \Rightarrow a=\frac{2}{\beta} \\ -5\frac{2}{2a}+\frac{6}{a}=a $$Usando as informações anteriores, podemos achar que:
$$ \frac{-5}{a}+\frac{6}{a}=a \\ \Rightarrow a^2=1 \Rightarrow a=\pm 1 $$ Resposta: a
Dados $u=(3,-1,2)$ e $v=(1,-2,-1)$ calculamos primeiro o produto escalar:
$$ u\cdot v=3\cdot 1 +(-1)\cdot (-2) + 2\cdot (-1)=3+2-2=3 $$O produto vetorial é dado por:
$$ u\times v= \begin{vmatrix} \hat{i} & \hat{j} & \hat{k} \\ 3 & -1 & 2 \\ 1 & -2 & -1 \end{vmatrix} = \\ \hat{i}(1+4)-\hat{j}(-3-2)+\hat{k}(-6+1)=(5,-5,-5) $$Resposta: a

Primeiro precisamos colocar a equação na forma:
$$ \frac{x^2}{a^2}+\frac{y^2}{b^2}=r^2 $$Podemos reescrever a equação original como:
$$ (x^2-2x+1)+(y^2+4y)=0 $$O primeiro termo $(x^2-2x+1)$ pode ser reescrito como $(x-1)^2$, bastando achar as raízes através da fórmula de Bhaskara. Completando o quadrado no termo $(y^2+4y)$, temos:
$$ y^2+4y+4-4=0 \\ \Rightarrow (y+2)^2-4 $$Logo
$$ (x-1)^2+(y+2)^2-4=0 \\ r=\sqrt{4}=2 $$Resposta: b

Para encontrar o gradiente no ponto dado, precisamos calcular as derivadas em cada variável, $(x,y,z)$, para $F$:
$$ \nabla F_x = \frac{\partial F}{\partial x}=2zx+e^z3x^2 \\ \nabla F_y = \frac{\partial F}{\partial y}=-z^5cos(y) \\ \nabla F_z = \frac{\partial F}{\partial z}=x^2+e^zx^3-5z^4sen(y) $$Calculando $\nabla F$ no ponto $(1,0,0)$, temos:
$$ \nabla F_x=2(1)(0)+e^03(1)^2=3 \\ \nabla F_y=-(0)^5cos(0)=0 \\ \nabla F_z=1^2+e^0(1)^3-5(0)^4sin(0)=1+1=2 \\ $$Logo, $\nabla F_{(1,0,0)}=(3,0,2)$.
Resposta: a

Sabendo os limites da curva, ou seja, $x$ entre 0 e 1 e $y=e^x$, podemos calcular a integral relacionada para obter a área:
$$ \int_{0}^{1} e^x dx=e^x\rvert_{0}^{1}=e^1-e^0=e-1 $$Resposta : a

Para resolver pelo método de Gauss, precisamos transformar a matriz original em uma matriz identidade, de modo que teremos os valores para $x,y$ e $z$. Começamos trocando as linhas 2 e 3:
$$ \left( \begin{array}{ccc|c} 1 & 2 & -3 & -2 \\ 2 & -1 & 2 & 3 \\ 3 & 0 & 1 & 0 \\ \end{array} \right) \\ \quad L_2\rightarrow -2L_1+L_2 \\ \left( \begin{array}{ccc|c} 1 & 2 & -3 & -2 \\ 0 & -5 & 8 & 7 \\ 3 & 0 & 1 & 0 \\ \end{array} \right) \\ \quad L_1\rightarrow (2/5)L_2+L_1 \\ \left( \begin{array}{ccc|c} 1 & 0 & 1/5 & 4/5 \\ 0 & -5 & 8 & 7 \\ 3 & 0 & 1 & 0 \\ \end{array} \right) \\ \quad L_3\rightarrow -3L_1+L_3 \\ \left( \begin{array}{ccc|c} 1 & 0 & 1/5 & 4/5 \\ 0 & -5 & 8 & 7 \\ 0 & 0 & 2/5 & -12/5 \\ \end{array} \right) \\ \quad L_1\rightarrow L_3/2+L_1 \\ \left( \begin{array}{ccc|c} 1 & 0 & 0 & 4 \\ 0 & -5 & 8 & 7 \\ 0 & 0 & 1 & -6 \\ \end{array} \right) \\ \quad L_2\rightarrow -8L_3+L_2 \\ \left( \begin{array}{ccc|c} 1 & 0 & 0 & 4 \\ 0 & 1 & 0 & -11 \\ 0 & 0 & 1 & -6 \\ \end{array} \right) $$Resposta : b

Para calcularmos o ângulo precisamos obter os coeficientes angulares de cada reta.
$$ 2x-y=12 \Rightarrow y=2x-12 \\ m_1=2 \\ 3x+y=-3 \Rightarrow y=-3x-3 \\ m_2=-3 \\ $$Calculamos o ângulo através da equação $\alpha = arctan(|\frac{m_1+m_2}{1+m_1\cdot m_2}|)$:
$$ \alpha = arctan(|\frac{5}{-5}|)=arctan(1)=45^\circ $$Resposta : d

Vamos fazer a redução por partes, lembrando que $B'$ é o complementar de $B$, ou seja, $x\in U \land x\notin B$:
$$ A\cup B'=x\in A \lor x\in B' \\ A\cap (A\cup B') = (A\cap A)\cup (A\cap B') = A\cup A = A \\ A-B'=x\in A \land x\notin B' = x\in A \land x\in B= A\cap B $$Resposta : c
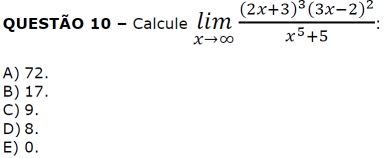
Podemos notar que esse é um tipo de limite no padrão $\frac{\infty}{\infty}$ pois ambos, numerador e denominador tem $x^5$. No limite de $x\rightarrow \infty$, os termos constantes e de potência menor que $x^5$ serão descartados, portanto:
$$ \lim_{x\rightarrow \infty} \frac{(2x+3)^3(3x-2)^2}{x^5+5}\sim \\ \sim \lim_{x\rightarrow \infty} \frac{(2x)^3(3x)^2}{x^5} = \\ = \lim_{x\rightarrow \infty} \frac{ 8x^39x^2}{x^5}=72 $$Resposta : a

Primeiro vamos escrever a frase em notação matemática. Seja $P(x)$ a propriedade do elemento $x$ que viajou:
$$ \exists! x \in (\text{Marcos, Heide}) | P(x) $$Quando negamos a declaração acima, obtemos:
$$ \nexists x \in (\text{Marcos, Heide}) | P(x) \lor x=\text{Marcos},y=\text{Heide} | P(x,y) $$Ou seja, a negação implica que ambos não viajaram ou ambos viajaram.
Resposta : d

Vamos transformar a frase em notação matemática. Seja $C$ o conjunto de cidades, $H(c)$ o conjunto de hospitais para uma cidade $c$ e $P(h)$ a propriedade de que um hospital $h$ tem ao menos 30 leitos.
$$ \exists\; c \in C \;|\; \forall \; h \in H(c) \;|\; P(h) $$Na primeira parte, "existe pelo menos uma cidade", a negação é dada por "não existe cidade", já que estamos negando "Existe uma ou mais cidades". Na segunda parte, "todos os hospitais possuem, pelo menos, 30 leitos", negamos com "existe ao menos um hospital que não possui, pelo menos, 30 leitos":
$$ \nexists \; c \;\in \;C \;|\; \exists \;h\; \in H(c) \;|\; !P(h) $$Isso se traduz em "em todas as cidades, há ao menos um hospital com no máximo 29 leitos".
Resposta : e

Esse é um problema de combinatória que pode ser resolvido pelo método dos traços e bolas: *|*|*|*. Usamos 3 barras para simbolizar a separação dos quatro amigos. Como cada um deve receber ao menos um convite, sobram 10-4=6, resultando em uma combinação de 6 convites restantes + 3 barras, 9, divididos entre 3 barras, ou seja:
$$ C(9,3)=\frac{9!}{(9-3)!3!}=\frac{9\cdot 8\cdot 7}{3\cdot 2}=12\cdot 7 = 84 $$Resposta : a

Usando as leis de DeMorgan, temos que $(a*b)'=a'+b'$, ou seja
$$ \overline{(\bar{E}*\bar{B})}=\bar{\bar{E}}+\bar{\bar{B}}=E+B $$Resposta : d

Vamos montar a tabela verdade para essa relação:
| $p$ | $q$ | ~$p$ | ~$q$ | $p\rightarrow q$ | ~$p\rightarrow q$ |
|---|---|---|---|---|---|
| V | V | F | F | V | F |
| F | V | V | F | F | V |
| F | F | V | V | V | F |
| V | F | F | V | F | V |
Pela tabela, na terceira linha, vemos que o único caso onde ambos são verdadeiros ao mesmo tempo e tem ~$p\rightarrow q$ falsa, é ~$p$ ou ~$q$.
Resposta : c

Primeiro podemos montar uma tabela verdade, com base na fórmula dada, para entendermos as relações entre a, b e c:
| A | B | C | f(ABC) |
| 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 |
| 0 | 1 | 0 | 0 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 0 | 0 |
| 1 | 0 | 1 | 1 |
| 1 | 1 | 0 | 1 |
| 1 | 1 | 1 | 1 |
Onde as linhas em vermelho representam o padrão encontrado na fórmula dada. O mapa de Karnaugh é o seguinte:
| AB | 00 | 01 | 11 | 10 | |
|---|---|---|---|---|---|
| C | 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 1 | 0 |
Deste mapa podemos obter a simplificação da fórmula através das células em vermelho, que representam, agrupando os elementos em comum, $AB + BC$.
Resposta : a

Esse é outro problema de análise combinatória. Considerando que as strings ternárias interessantes tem 2 dígitos em cada uma das 7 casas e 1 dígito na casa onde tem o número 1, temos, $2^7*8=1024$ números distintos. Porém, temos que adicionar o caso onde não temos o número 1, somente os dígitos 0 e 2, ou seja, $2^8=256$. O total é $1024+256=1280$.
Resposta : d
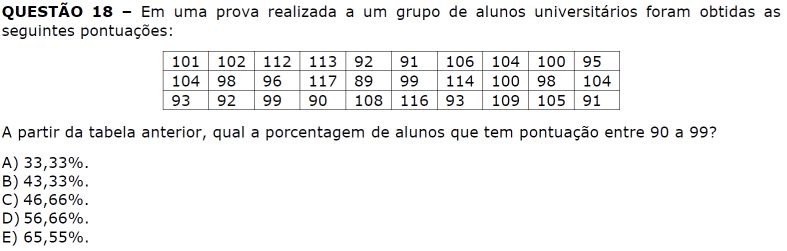
A quantidade de pontuações entre 90 e 99 é: 13. Essa contagem é inclusiva, ou seja, estamos contando pontuações iguais à 90 ou 99. A quantidade total é 30. Logo, a porcentagem pode ser calculada:
$$ P_{90-99} = \frac{13}{30} = 43,33% $$Resposta : e

Podemos resolver esse problema lembrando que as três últimas casas devem refletir os dígitos das três primeiras casas (ou o inverso), por exemplo:
_ _ _ _ _ _ = 122 221
Um número é divisível por 4 caso termine em 00 ou os últimos 2 dígitos sejam divisíveis por 4. Se fixarmos o último dígito com um número par, que não pode ser zero pela regra da primeira casa, também teremos um número par na primeira casa. Na penúltima casa podemos ter 10 dígitos, assim como na terceira casa. Neste caso, o número de dígitos em cada posição seria:
- 1ª posição: 1 dígito
- 2ª posição: 1 dígito
- 3ª posição: 10 dígitos
- 4ª posição: 1 dígito
- 5ª posição: 10 dígitos
- 6ª posição: 4 dígitos
O que dá:
$$ 10^2\times 4 = 400 $$Porém, nem todas as combinações de 10 dígitos com os 4 pares, nas duas últimas casas, são divisíveis por 4, ou seja, dos 40 somente usamos 20, que são: 04, 08, 12, 16, 24, 28, 32, 36, 44, etc., excluindo sempre os de final 0 da tabuada do 4.
Logo, ficamos com 200 números.
Resposta : b

A esperança pode ser calculada pela fórmula:
$$ E[X]=\sum_{i}^{n} P(i)x_i $$Como já temos a probabilidade de cada item, só devemos executar a soma:
$$ E[X]=2\times 0,05 + 3\times 0,10 + 4\times 0,10 + \\ 5\times 0,2 + 6\times 0,25 + 7\times 0,3 = 5,4 $$Resposta : e

O algoritmo de ordenação merge sort utiliza o método de divisão e conquista para reduzir a lista original em subpartes independentes, ordena cada parte e depois junta (merge) os pedaços. Esse primeiro passo, de dividir a lista pela metade, depois a metade da metade e assim por diante, em problemas independentes, é conhecido como divisão e conquista.
A árvore geradora mínima de Kruskal é usado para encontrar a árvore geradora mínima de um grafo ponderado conectado, isto é, um subconjunto de arestas do grafo original que conecta todos os vértices minimizando o peso total. Ele vasculha todas as rotas possíveis e seleciona, dentre um subconjunto levantado de rotas, as que minimizam o peso, ou seja, é um algoritmo tipo guloso (greddy).
O algoritmo de Floyd-Warshall é utilizado para encontrar caminhos mais curtos entre todos os partes de vértices em um grafo ponderado. Ele utiliza programação dinâmica, que é uma forma de abordar problemas que tem subproblemas que, quando sobrepostos, remontam o problema original.
Resposta: e

A função fatorial, $n!$, é a que cresce mais rapidamente. Isso pode ser demonstrado calculando o limite em comparação com as outras funções:
$$ \lim_{n\rightarrow \infty} \frac{n!}{n}=\lim_{n\rightarrow \infty} \frac{n(n-1)}{n}=\lim_{n\rightarrow \infty} n-1 \rightarrow \infty \\ \lim_{n\rightarrow \infty} \frac{n!}{2^n} \rightarrow \infty \\ \lim_{n\rightarrow \infty} \frac{n!}{n^2} \rightarrow \infty \\ $$Sabemos que $O(n)$, linear, é a mais rápida, então precisamos tirar o limite entre $2^n$ e $n^2$.
$$ \lim_{n\rightarrow \infty} \frac{2^n}{n^2}\rightarrow \infty $$Que pode ser resolvido pela regra de L'Hopital. Então, por ordem crescente, temos:
$$ O(n) < O(n^2) < O(2^n) < O(n!) $$Resposta: c

Uma lista linear é uma estrutura de dados que armazena os elementos de forma sequencial, ou seja, um após o outro sem espaços entre eles. A vantagem é poder acessar qualquer item por um índice, em tempo fixo. A desvantagem é principalmente em eficiência para mover ou remover itens, o que envolve deslocar elementos para o próximo índice com espaço suficiente. Os exemplos de estruturas de dados lineares são: pilha (stack), fila (queue), listas e strings.
A - Nessa estrutura só é necessário manter um ponteiro para o topo da pilha. Item incorreto.
B - A lista linear é ineficiente em inserções e remoções constantes, como falado no começo da resposta. Item incorreto.
C - Uma lista encadeada (linked list) é uma estrutura de dados onde cada elemento tem um nó para o próximo, de forma não linear, ou seja, não usa espaços em memória contíguos. Item correto.
D - Esse seria o caso de uma lista circular. Item incorreto.
E - A fila é modelo inverso da pilha, isto é, o primeiro a ser inserido é o primeiro a sair. Logo, um ponteiro deve ser utilizado no fim da fila. Item incorreto.
Resposta: c

A - O algoritmo de inserção utiliza dois vetores para ordenar uma lista: uma com valores já ordenados e outra com os valores originais. Cada iteração efetua comparações para posicionar um valor da lista original na lista ordenada. Item incorreto.
B - Fila de prioridade (Priority Queue) não é um algoritmo em si, mas uma estrutura abstrata de dados (ADT = Abstract Data Type) que fornece acesso eficiente aos elementos máximo e mínimo. Os elementos são organizados por prioridade. Uma implementação comum dessa ADT é através da heap, que tem essa propriedade de hierarquia de elementos, como uma árvore. Item correto.
C - Quicksort é um algoritmo que segue uma abordagem divisão e conquista, onde um elemento chamado "pivô" é selecionado e a lista é particionada em duas, separando os valores maiores ou menores que o pivô. Pode ser programado como um algoritmo recursivo. Item incorreto.
D - Shellsort modifica o algoritmo de inserção em casos onde a lista de ordenação é grande. Utiliza um processo de comparação dos elementos, normalmente em potências de dois, para ordenar a lista parcialmente. Item incorreto.
E - O algoritmo de seleção pesquisa o maior ou menor elemento na lista e o posiciona no começo da parte ainda não ordenada e isso é feito até a lista toda é ordenada. Item incorreto.
Resposta: b

A - Item correto. Algortimos recursivos demandam a solução de uma relação matemática de recorrência, ou seja, como o tamanho da entrada afeta o número de chamadas recursivas. Deve-se também contar o número de operações em cada chamada, identificando os casos médios e piores. Depois disso convertemos a solução em notação Big O.
Resposta: a

A - O algoritmo de Huffman é um algoritmo de compressão de dados desenvolvido por David Huffman em 1952. Ele é amplamente utilizado para compactar dados, como arquivos de texto, imagens e áudio, quando há distribuição de frequência desigual, reduzindo o espaço necessário para armazenamento ou transmissão desses dados. Item correto.
B - Tabelas Hash são utilizadas para armazenamento e recuperação eficiente de informações, normalmente em uma estrutura tipo chave-valor. Item incorreto.
C - Um índice é um tipo de estrutura de dados auxiliar que faz um mapeamento de valores-chave para uma posição ou localização física correspondente ao dado. Servem para agilizar buscas. Item incorreto.
D - O algoritmo LZW também é utilizado para compressão, mas quando há padrões repetitivos. Item Incorreto.
E - O objetivo do algoritmo de aproximação de entropia é calcular uma estimativa razoável da entropia de uma fonte de dados sem a necessidade de analisar todos os seus elementos. A entropia é uma medida da quantidade de informação contida em um conjunto de dados, e a sua estimativa é útil em diversas áreas, como compressão de dados, criptografia e análise de padrões. Item Incorreto.
Resposta: a
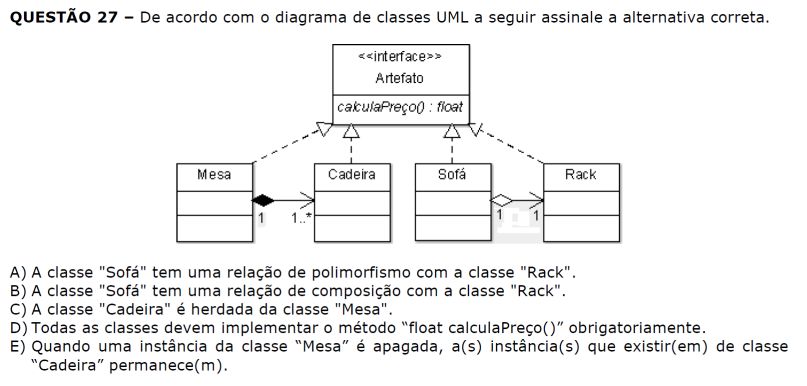
A - A relação entre Sofá e Rack é de associação. Item incorreto.
B - Idem anterior. Item incorreto.
C - A relação entre Cadeira e Mesa é de composição. Item incorreto.
D - As classes herdam da interface Artefato e devem implementar o método calcularPreco(). Item correto.
E - Na relação de composição, a classe parte ou filha, Cadeira, não pode existir independente da classe pai, Mesa. Item incorreto.
Resposta: d

Vamos quebrar o código e explicar cada linha:
- int *p, **r, a = -1, c, b = 10;
Esta linha declara múltiplas variáveis:
p é um ponteiro para um número inteiro.
r é um ponteiro para um ponteiro para um inteiro.
a é um número inteiro inicializado com -1.
c é um número inteiro.
b é um inteiro inicializado com 10. - p = &a;
Esta linha atribui o endereço da variável a ao ponteiro p. - r = &p;
Esta linha atribui o endereço do ponteiro p ao ponteiro r. - c = **r + b--;
Esta linha realiza várias operações:
**r desreferencia o ponteiro r duas vezes, acessando o valor apontado por p, que é o valor de a (-1).
b-- pós-decrementa o valor de b em 1, então o valor de b torna-se 9 após esta operação.
O valor de **r (-1) é adicionado ao valor de b (10), resultando em c sendo atribuído o valor 9. - printf("%d", c);
Essa linha imprime o valor de c usando o especificador de formato %d, que representa um número inteiro, resultando na exibição da saída "9" na tela.
Resposta : c

Vamos avaliar cada afirmação:
I - Essa método não é eficiente quando há muitos caracteres não repetitivos nos dados, ou seja, quando aumentamos o número de diferentes elementos possíveis, de números ou letras para alfanuméricos, o algoritmo deixa de ser vantajoso. Item verdadeiro.
II - O arquivo tipo bitmap gera uma sequência de pixeis que representa a imagem. O algoritmo RLE é bem eficiente nesse caso pois há grande possibilidade de pixeis iguais lado a lado, ou seja, que podem ser agrupados para reduzir o tamanho final da imagem. Item verdadeiro.
III - Falso. Como falado anteriormente, o RLE é útil quando há uma sequência repetitiva de caracteres.
Resposta: d

Variáveis reais (float, double): As variáveis reais são utilizadas para armazenar números com casas decimais. Elas são especialmente úteis quando precisamos trabalhar com valores fracionários ou representar grandezas contínuas. Existem dois tipos comuns de variáveis reais: float e double. O tipo float armazena números em ponto flutuante de precisão simples, enquanto o tipo double armazena números em ponto flutuante de precisão dupla, oferecendo uma maior precisão e amplitude de valores. As variáveis reais são amplamente utilizadas em cálculos científicos, financeiros e de engenharia.
Variáveis de caracteres (char, string): As variáveis de caracteres são usadas para armazenar caracteres individuais ou sequências de caracteres. O tipo de variável mais comum para armazenar um único caractere é o char. Ele pode representar letras, números, símbolos especiais e até mesmo caracteres de controle. Já as sequências de caracteres podem ser armazenadas em variáveis do tipo string, que é uma sequência de chars. As variáveis de caracteres são frequentemente utilizadas para manipular textos, exibir mensagens e lidar com entradas de usuário.
Variáveis inteiras (int): As variáveis inteiras são utilizadas para armazenar números inteiros, ou seja, números sem casas decimais. Elas podem representar valores positivos, negativos ou até mesmo zero. Em muitas linguagens de programação, as variáveis inteiras têm um tamanho fixo, o que significa que elas podem armazenar apenas uma faixa específica de valores, dependendo do número de bits alocados para elas. Essas variáveis são frequentemente utilizadas em operações matemáticas, contagens e para representar índices de arrays.
Todas as afirmações estão corretas.
Resposta: e
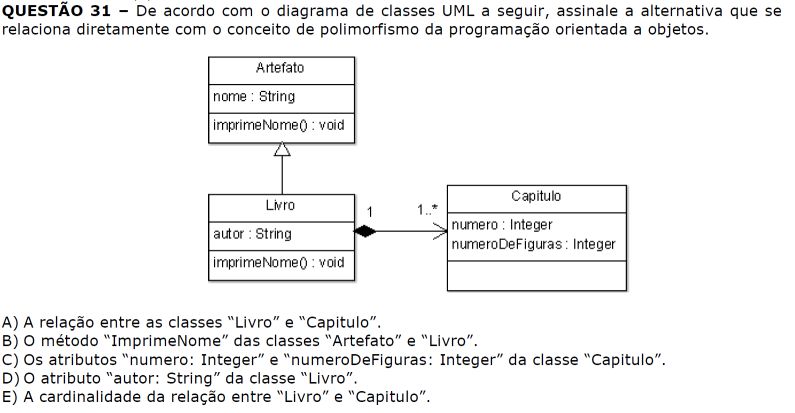
Em termos simples, o polimorfismo permite que uma classe base seja estendida por classes derivadas que compartilham a mesma interface ou herança. Isso significa que as classes derivadas podem substituir ou estender o comportamento dos métodos da classe base, permitindo que diferentes objetos sejam tratados de forma polimórfica.
Com base nisso, a única resposta que relaciona o método imprimeNome() com as classes é a B.
Resposta: b

Um grafo completo é um tipo especial de grafo em que cada par de vértices é conectado por uma aresta. Em outras palavras, todos os vértices de um grafo completo estão conectados entre si.
Resposta : b

A - O comando while é um laço e não serve para bifurcar um código. Item incorreto.
B - O else não é obrigatório depois de um if. Item incorreto.
C - Quando a condição é verdadeira, o bloco do if é executado. Item incorreto.
D - Como há dois blocos, um do if e outro do else, um dos dois não será executado. Item correto.
E - Podemos ter quantos if-else em cada if ou else. Item incorreto.
Resposta: d

Alocação Encadeada: Neste método, os blocos de dados são ligados em sequência. Cada bloco de dados contém o conteúdo real do arquivo e um ponteiro para o próximo bloco de dados.
Alocação Indexada: Neste método, cada arquivo possui um bloco de índice associado a ele. O bloco de índice contém uma tabela de índices, onde cada entrada aponta para um bloco de dados correspondente ao arquivo. A alocação indexada permite que os blocos de dados sejam espalhados pelo disco, pois o bloco de índice atua como um índice para localizá-los.
Com base no exposto acima, a afirmação III é incorreta.
Resposta: d

A - Uma das principais características da árvore B+ é a sua capacidade de lidar com eficiência consultas por intervalo. Os nós folha são ligados em uma lista duplamente encadeada, permitindo a busca sequencial eficiente de dados. Item correto.
B - A árvore binária de pesquisa tem a propriedade de que o valor de qualquer nó à esquerda é menor do que o valor do próprio nó, enquanto o valor de qualquer nó à direita é maior. Item incorreto.
C - É amplamente utilizado para implementar a busca rápida e eficiente de elementos por uma chave (hash). Item incorreto.
D - A árvore AVL mantém a propriedade de balanceamento, que garante que a diferença de altura entre as subárvores esquerda e direita de qualquer nó seja no máximo 1. Item incorreto.
E - Também conhecida como Trie, é uma estrutura de dados especializada na busca eficiente de palavras ou strings. Item incorreto.
Resposta: a

A matriz descrita é chamada de adjacência.
Resposta: c

A - Não é uma busca em si, mas um método de ordenação de vértices. Item incorreto.
B - Explora os vértices na "horizontal", explorando os nós vizinhos antes dos adjacentes e filhos.
C - É uma variação da busca em largura. Item Incorreto.
D - É uma variação da busca em profundidade que realiza a ação de visitar o vértice após explorar seus filhos. Item incorreto.
E - Item correto.
Resposta: e

A única opção que permite repetição é um laço.
Resposta : a

Precisamos determinar a expressão regular (r) que gera a mesma linguagem (L(r) = L(G)).
Analisando as regras de produção, podemos observar o seguinte:
- A regra S -> abS indica que podemos ter um "ab" seguido por uma ocorrência de S.
- A regra S -> S indica que podemos ter mais ocorrências de S.
- A regra S -> a indica que podemos ter um "a" isolado.
Com base nessas observações, podemos construir a expressão regular que representa a mesma linguagem:
r = (ab)*a
Essa expressão regular indica que podemos ter zero ou mais ocorrências de "ab", seguidas obrigatoriamente por um "a".
Resposta: a
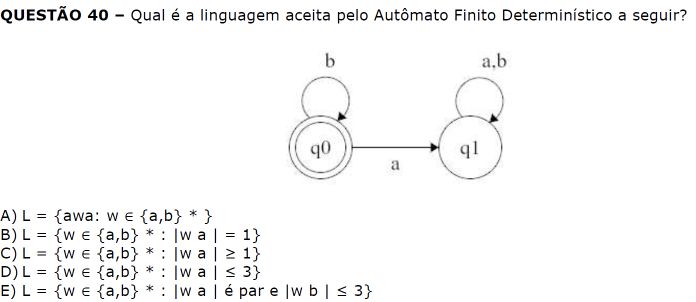
Questão anulada.

A ideia central do lema do bombeamento é que se uma linguagem é regular, então qualquer palavra suficientemente longa pertencente a essa linguagem pode ser dividida em partes que podem ser repetidas um número arbitrário de vezes, mantendo-se dentro da linguagem.
I - Autômatos finitos são modelos computacionais para linguagens regulares. Item verdadeiro.
II - Isso é verdade se o autômato tiver n estados, como mencionado no item anterior. Item verdadeiro, apesar de confuso.
III - Essa assertiva está correta e alinha-se com as condições estabelecidas pelo lema do bombeamento para linguagens regulares. De acordo com o lema do bombeamento, se uma linguagem L é regular, então existe um número positivo p (o pumping length) tal que toda palavra w pertencente a L, com |w| ≥ p, pode ser dividida em cinco partes uvxyz. Item verdadeiro.
IV - Falso, conforme definição inicial.
Resposta: c

Vamos montar a tabela verdade para a expressão dada:
| A | B | C | f(A,B,C) |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 |
| 0 | 1 | 0 | 0 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 |
| 1 | 0 | 1 | 1 |
| 1 | 1 | 0 | 0 |
| 1 | 1 | 1 | 0 |
Podemos notar, contando do 0 em diante, que as linhas 1, 4 e 5 têm valor verdadeiro (1). Portando, a resposta é: $\Sigma m(1,4,5)$.
Resposta: b
Um flip-flop J-K é um tipo de circuito lógico sequencial que pode armazenar e manipular informações binárias. É composto de múltiplas portas lógicas e é comumente usado em eletrônica digital e sistemas de computador para diversos fins, incluindo armazenamento de dados, divisão de frequência e geração de sinal de controle.
O flip-flop J-K tem duas entradas: J (set) e K (reset). Também possui duas saídas: Q (saída normal) e Q̅ (saída complementar). O estado do flip-flop é determinado por suas entradas atuais (J e K) e seu estado anterior.
Vamos nomear cada flip-flop e trilha, conforme imagem abaixo:
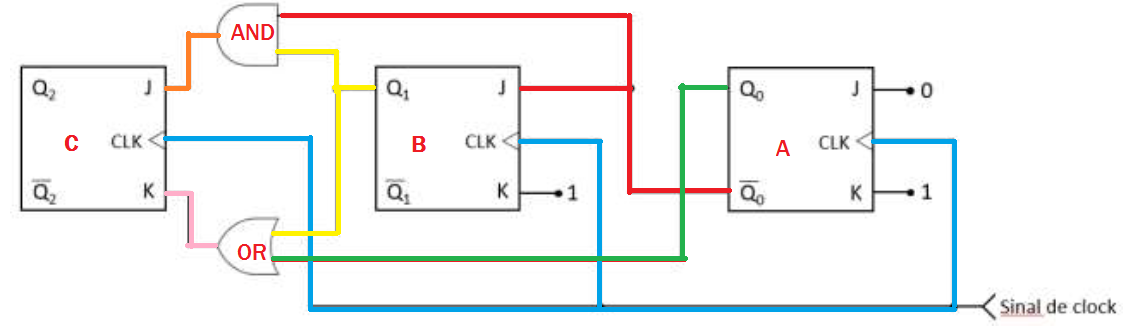
A tabela abaixo exibe os dois estados do problema:
| Clock | A-J | A-K | A-$Q_0$ | A-$\bar{Q_0}$ | B-J | B-K | B-$Q_1$ | B-$\bar{Q_1}$ | C-J | C-K | C-$Q_2$ | C-$\bar{Q_2}$ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | 1 | 1 | 0 | 0 | 0 | 1 | 1 | N/A | 0 | 0 | 0 | 0 |
| T+1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | N/A | 0 | 0 | 1 | 0 |
Resposta: d

Na política write-through, a CPU sempre grava em cache e depois em memória. Na política write-back, a CPU grava o dado no cache primeiro, marca-o com um bit de controle para ser atualizado na memória RAM posteriormente. O dado só será escrito na RAM quando o bloco que o armazena for atualizado.
Para que a cache write-back seja mais eficiente do que a cache write-through, o custo total de transferência de dados na cache write-back deve ser menor ou igual do que o custo total na cache write-through. Portanto, o custo total de transferência de dados é igual ao tamanho da linha da cache (16 bytes).
Resposta: d

"Área de troca" de memória virtual se refere ao espaço reservado em outro meio mais lento que a RAM, quando esta é insuficiente para armazenar os dados dos programas, para, por exemplo, o disco rígido, onde uma ou mais páginas do espaço de endereços são copiadas. Esse processo pode ser confundido com o swapping, que é copiar todo o processo de espaço de endereços para o disco.
Resposta: d

A função fork() cria um novo processo, que é uma cópia exata do processo pai, incluindo todas as variáveis e seu estado.
Se a função fork() retornar um valor maior que zero, isso significa que o processo atual é o pai e a função fork() criou um novo processo filho. Nesse caso, o pai incrementará a variável $i$ uma vez (i++).
Se a função fork() retornar zero, isso significa que o processo atual é o filho. Nesse caso, o filho também incrementará a variável $i$ uma vez.
Após as condições if/else temos outro incremento de $i$ (i++).
Como o método main é executado apenas uma vez e não há um laço dentro dele, tanto faz se o fork é pai ou filho, vamos ter a variável $i$ incrementada para $2$ e a impressão desse valor na tela.
Resposta: b

I - Para calcular o armazenamento, primeiro calculamos o total de espaços de memória: $2^{16}=65536$. Depois multiplicamos esse número pela o tamanho de cada célula de memória, no caso, 16 bits:
- $2^{16}=65536 \Rightarrow 65536\cdot 16$=$1048576 \;\text{bits}$
- $=1048576\; \text{bits} \;\cdot 1 \;\text{byte}/8 \;\text{bits}$
- $=131072\; 1\; \text{Kibibyte}/1024 \;\text{bytes} = 128\; \text{kByte}$
Item Correto.
II - Precisamos converter $2^{11}$ em hexadecimal para saber o último endereço. Em decimal usamos $2^{11-1}=2047$, que podemos representar em base 16 (usando o módulo %):
- 2047 % 16 = 15 (F)
- 127 % 16 = 15 (F)
- 7 % 16 = 7 (7)
Logo, o último endereço é $7FF_{16}$. Item correto.
III - RAM é um tipo de memória volátil, os outros não voláteis. Item incorreto.
Resposta: d

A - Um barramento de dados em uma placa-mãe é uma via de comunicação que permite a transferência de dados entre os componentes do sistema. É um conjunto de linhas ou trilhas elétricas que permite que os dados sejam transmitidos de uma parte do computador para outra. Item correto.
B - O barramento de dados da placa-mãe é usado principalmente para transferências de dados entre a memória, o processador e outros dispositivos conectados diretamente à placa-mãe, mas não para acessar diretamente os dados do disco. O acesso ao disco é feito normalmente através de um controlador. Item incorreto.
C - As linhas de endereço são parte do barramento de endereço, que é responsável por enviar sinais de endereço para a memória e outros dispositivos conectados à placa-mãe. Item correto.
D - As linhas de controle são responsáveis por várias funções essenciais, como iniciar ou encerrar uma operação de leitura ou gravação na memória, sinalizar interrupções para o processador, controlar o fluxo de dados entre os componentes, gerenciar o ciclo de busca e execução de instruções do processador, entre outras tarefas. Item correto.
E - Item incorreto.
Resposta : b
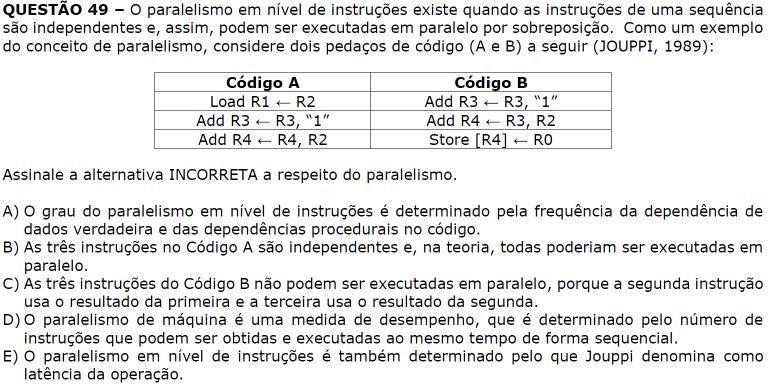
A resposta incorreta é o item D pois o paralelismo é justamente o oposto de sequencial, as instruções são executadas de forma "paralela" ou simultaneamente com outras. Um processo sequencial é tal que cada instrução é executada depois de outra.
Resposta : d

Essa questão está relacionada com a memória virtual criada pelo sistema operacional. Quando uma aplicação pede para acessar um endereço em memória e ele não está mapeado na RAM, o SO pode buscar a página pendente em disco e copiar seu conteúdo para a memória principal. A página possui um bit de gatilho quando se tenta alterá-la e assim uma cópia deve ser feita.
Resposta : c

Vamos analisar as afirmações:
I - Essa assertiva está correta. Um escalonamento recuperável permite a restauração do banco de dados a um estado consistente em caso de falha, enquanto um escalonamento serializável permite que as transações sejam executadas individulamente mantendo o banco de dados consistente, ou seja, sem necessidade de ser recuperável. Portanto, esses dois conjuntos não têm elementos em comum.
II - Essa assertiva está incorreta. A união entre os escalonamentos serializáveis e seriais não resulta apenas nos escalonamentos serializáveis. Escalonamentos seriais são um subconjunto dos escalonamentos serializáveis, mas nem todos os escalonamentos serializáveis são seriais.
III - O conjunto de escalonamentos não seriais está contido no conjunto de escalonamentos não serializáveis. Isso significa que todos os escalonamentos não seriais também são não serializáveis. Portanto, essa assertiva está correta.
IV - O conjunto de escalonamentos seriais não contém o conjunto de escalonamentos não recuperáveis pois um escalonamento não recuperável tem execuções concorrentes.
Resposta : c

Vamos analisar cada resposta:
A - É um tipo de algoritmo de aprendizado de máquina usado para regressão e classificação. Seus nós representam um atributo e cada ramo uma regra de decisão. Item incorreto.
B - O algoritmo normalmente utilizado em um classificador Bayesiano é o de Naive Bayes, onde, assumindo a independência entre os atributos de um elemento, queremos saber qual a sua classe (conjunto) mais provável que ele pertença. De forma matemática, dado $x$ um elemento e $C_i$ uma classe:
$$ P(C_i | x) = \frac{p(x|C_i)P(C_i)}{p(x)} \\ p(x|C_i)=\prod_{j=1}^{d}p(x_j|C_i),\quad i=1,2,...,k $$Que pode ser utilizado para estimar, através da regra de Bayes, se um elemento $x$ pertence ao conjunto $C_i$. Estimamos as probabilidades de uma distribuição, o que não é relacionado à descrição dada. A classificação é dada por uma evidência de qual conjunto é mais provável.
$$ C_m=\text{argmax}_{i\in \{1,...,M\}} p(C_i)\prod_{j=1}^d p(x_j | C_i) $$Item incorreto.
C - SVMs (Support Vector Machines), como são conhecidos, é uma teoria de aprendizado estatístico (TAE) dentro da área de aprendizado de máquina. O conceito de "margens" é importante para delimitar as regiões analisadas, por exemplo, um rio entre duas porções de terra. As condições matemáticas ajudam a escolher um bom algoritmo para a classificação. Seja $H$ o conjunto de possíveis classificadores, um algoritmo AM é utilizado para um conjunto de treinamento X. O classificador h exige análise de desempenho e complexidade, minizando o risco esperado (erro). O classificador tem desempenho ótimo quando se tem a convergência para o erro esperado. Isso não ocorre normalmente quando o conjunto de dados é pequeno. Item correto.
D - Uma rede neural é um modelo de aprendizado de máquina que simula o sistema cerebral humano, através de elementos, ou unidades de processamento, chamadas de neurônios artificiais ou nós, interconectados em camadas ocultas e de saída. Item incorreto.
E - As regras de associação visa descobrir padrões e relações entre itens em conjunto de dados através da frequência estatística e probabilidade condicional. Item incorreto.
Resposta : c

Vamos analisar as afirmações:
I - A segunda parte da frase, que fala sobre Adaptação ao Ambiente, está incorreta. Esse é um tipo de requisito não-funcional que especifica quais ambientes o software deverá funcionar corretamente. Item Incorreto.
II - Isso é verdadeiro. Há diversos estudos explicando o motivo de custar mais caro "arrumar" um software depois de entregue comparado com o período de desenvolvimento.
III - É uma afirmação confusa, mas refatoração não necessariamente é usada em sistemas legados, pode ser feita em qualquer sistema. Item incorreto.
Resposta : b

-
(V) Os roteadores precisam implementar até a camada de rede para executar a sua função, porque o encaminhamento de pacotes requer conhecimento de cabeçalhos dessa camada.
- Essa afirmação é verdadeira. Os roteadores são dispositivos de rede que operam na camada de rede do modelo OSI (ou na camada de rede do modelo TCP/IP). Eles precisam entender e processar os cabeçalhos dos pacotes IP para realizar o encaminhamento adequado.
-
(V) A arquitetura TCP/IP executa a função de controle de congestionamento na camada de transporte.
- Essa afirmação é verdadeira. O controle de congestionamento é uma função realizada na camada de transporte do modelo TCP/IP. O protocolo TCP (Transmission Control Protocol) implementa mecanismos de controle de congestionamento para evitar que a rede fique sobrecarregada.
-
(F) O controle de acesso ao meio é função da camada de rede.
- Essa afirmação é falsa. O controle de acesso ao meio é uma função realizada na camada de enlace de dados do modelo OSI (ou na subcamada de acesso ao meio da camada de enlace de dados do modelo TCP/IP). Essa camada lida com a transmissão confiável de dados entre nós adjacentes em uma rede local, incluindo o gerenciamento do acesso ao meio físico de transmissão.
-
(F) A camada de transporte é fundamental para esconder detalhes dos meios físicos de transmissão da camada de sessão.
- Essa afirmação é falsa. A camada de transporte não tem a função de esconder detalhes dos meios físicos de transmissão da camada de sessão. A camada de transporte é responsável pela entrega confiável de dados entre processos de aplicação em diferentes hosts. Ela fornece serviços de segmentação, controle de fluxo e controle de erros.
Resposta : b

As operações descritas no problema podem ser definidas como:
- Projeção: permite selecionar apenas determinadas colunas de uma relação, descartando as demais. Usa o símbolo $\pi$.
- Seleção: é utilizada para filtrar as tuplas de uma relação com base em uma condição. Usa o símbolo $\sigma$.
- Produto cartesiano: é uma operação que combina todas as tuplas de duas relações em uma nova relação. Usa o símbolo $x$.
- Renomeação: permite atribuir novos nomes às colunas de uma relação. Usa o símbolo $\rho$.
Traduzindo então a consulta:
- PROD x $\rho$ CLONE (PROD) : Calcule o produto cartesiano entre PROD e ela mesma, renomeada para CLONE
- $\sigma$ PROD.Preco < CLONE.Preco: Filtra os registros por uma comparação entre a tabela com ela mesma, ou seja, busca os elementos com preços menores do que o maior valor existente. Isso fica mais claro quando notamos que o uso do operador $<$ ao invés de $\leq$.
- $\pi$ PROD.CODIGO : Seleciona o código dos itens encontrados.
Resposta : e

Vamos analisar as afirmações em ordem:
I - Esse é um tipo de requisito não funcional imposto pela organização que usará o software, ou seja, uma consideração interna, relacionada com políticas, procedimentos, regulamentos, etc...
II - É um requisito externo, fora do controle do desenvolvedor, exigindo uma adaptação à legislação, por exemplo, para funcionar.
III - É um requisito de produto, relacionado com exigências dos usuários, afetando usabilidade, desempenho, etc...
Resposta : d

I - Uma superfície é um objeto matemático de duas dimensões. Quando aplicamos texturas, normalmente utilizamos formas geométricas como triângulos, ou outros polígonos, mas que têm duas dimensões. Item Correto.
II - Uma textura procedural utiliza uma relação matemática (um algoritmo, por ex) ao invés de dados armazenados. Item correto.
III - Bump mapping é uma técnica de perturbação de superfície para variar a intensidade de luz refletida por um pixel. Item incorreto.
Resposta : c

A - É um modelo de iluminação aplicado nos vértices do polígono e as cores destes vértices são interpoladas sobre a superfície do polígono.
B - Modelo de iluminação que é aplicado em cada ponto do polígono. Isso é possível graças à interpolação das normais dos vértices em cada pixel da superfície. É uma técnica de iluminação mais avançada e precisa em relação à tonalização de Gouraud
C - A tonalização constante é a técnica mais simples de iluminação em computação gráfica. Nesse método, todas as faces do objeto são preenchidas com uma única cor, independentemente de sua orientação, posição da fonte de luz ou normais do objeto.
D - A tonalização linear é uma técnica intermediária entre a tonalização constante e a tonalização de Gouraud. Nesse método, as cores são interpoladas linearmente entre os vértices de cada face do objeto, mas sem levar em conta as normais ou a posição da fonte de luz.
E - A tonalização com correção gama é uma técnica utilizada em computação gráfica para compensar as diferenças de brilho exibidas pelos monitores de vídeo. Ela leva em consideração a não linearidade da relação entre os valores de intensidade das cores no sistema de cores RGB (Red, Green, Blue) e a luminância percebida pelo olho humano.
Resposta : b

I - Esse item está correto. Para restaurar a imagem corrompida, precisamos compreender minimamente como ocorreu a degradação para poder reverter o problema.
II - Item correto. Nesse método, o observador tem a capacidade de interagir e ajustar os parâmetros de restauração em tempo real para obter o resultado desejado. Ao contrário dos métodos automáticos de restauração de imagem, nos quais os parâmetros são definidos de antemão, a restauração interativa permite que o observador influencie o resultado final de acordo com sua percepção visual e preferências específicas.
III - Item incorreto. Não temos "total conhecimento" sobre a percepção visual humana.
IV - Correto. Transformações geométricas servem para aplicar mudanças espaciais nos elementos da imagem (rotação, translação, reflexão).
V - Incorreta. Essas são técnicas de processamento de imagem.
Resposta : d

Para determinar o valor de Y, precisamos identificar o prefixo da sub-rede do Setor B. O prefixo é uma representação numérica que define a quantidade de bits usados para identificar a rede em um endereço IP.
Um endereço IP (Internet Protocol) é composto por 32 bits, que são divididos em duas partes: a parte de identificação da rede e a parte de identificação do host.
A parte de identificação da rede especifica qual rede o dispositivo está conectado, enquanto a parte de identificação do host identifica um dispositivo específico dentro dessa rede.
Observando os intervalos de endereços IP fornecidos, podemos notar que ambos os intervalos estão na mesma rede IP de 194.24.0.0/20. O prefixo /20 indica que os primeiros 20 bits são usados para identificar a rede, enquanto os 12 bits restantes são usados para identificar os hosts.
Portanto, o valor de Y é 20, indicando que os primeiros 20 bits são usados para identificar a rede no Setor B.
Resposta : b

A - A codificação aritmética permite a representação de sequências de símbolos usando uma fração do número médio de bits por símbolo.
B - É baseado em codificação de entropia e tem como objetivo codificar números inteiros não negativos em que se verifica que a probabilidade de ocorrência é menor quanto maior for o número.
C - A codificação de Huffman é uma técnica de compressão de dados que utiliza a construção de uma árvore de Huffman para atribuir códigos de tamanho variável aos símbolos. Os símbolos mais frequentes recebem códigos mais curtos, enquanto os símbolos menos frequentes recebem códigos mais longos.
D - A codificação wavelet é uma técnica utilizada para comprimir dados, especialmente imagens, explorando as propriedades da transformada wavelet. A transformada wavelet divide a imagem em diferentes frequências e resoluções, permitindo que detalhes importantes sejam preservados enquanto informações redundantes são descartadas.
E - A codificação de planos de bits é uma técnica que aproveita a estrutura de um dado binário para comprimi-lo. O dado é dividido em planos de bits, onde cada plano representa um conjunto de bits relacionados a uma determinada posição ou função.
Resposta : e

O conceito de alternar entre diferentes processos é chamado de multiprogramação. A ideia central da multiprogramação é permitir que vários programas residam na memória ao mesmo tempo e compartilhem os recursos do sistema de forma concorrente. Em vez de esperar que um programa termine sua execução para que outro possa ser carregado e executado, a multiprogramação permite que múltiplos programas sejam carregados na memória simultaneamente.
Resposta : b

Uma gramática G é composta dos seguintes parâmetros:
- V - Variáveis não-terminais
- $\Sigma$ - Símbolos Terminais
- P - Regras de produção
- S - Variável inicial
O P pode ser expresso como:
A regra de produção S ::= (S) S indica que o símbolo S pode ser substituído pela sequência (S)S. Isso significa que, durante a derivação de uma cadeia a partir do símbolo inicial S, pode ocorrer a expansão de S como (S)S.
A regra de produção S ::= ε indica que o símbolo S também pode ser substituído pela sequência vazia, representada por ε. Isso significa que, durante a derivação de uma cadeia, o símbolo S pode ser omitido, resultando em uma cadeia vazia.
Essa gramática é reconhecida por um autômato de pilha, que possui memória adicional, em comparação com autômatos finitos comuns.
Resposta : d

Quando uma transação é iniciada, ela pode realizar várias operações de leitura e escrita nos dados do banco. Durante essa transação, as atualizações feitas são mantidas temporariamente em uma área de trabalho separada, conhecida como área de trabalho da transação. Essas atualizações temporárias não são visíveis para outras transações concorrentes ou usuários do sistema.
É importante destacar que as atualizações temporárias só se tornam permanentes e visíveis para outras transações quando a transação que as realizou é confirmada ou finalizada com sucesso. Em caso de falha na transação, as atualizações temporárias são descartadas e desfeitas, garantindo a consistência do banco de dados.
Resposta : e

O UDP é um protocolo simples e de baixa sobrecarga em comparação com o TCP. Ele oferece um serviço não orientado a conexão, o que significa que não estabelece uma conexão antes de transmitir os dados. Isso o torna mais leve em termos de processamento e latência, mas também o torna menos confiável em relação à entrega de dados. Diferentemente do TCP, o UDP não garante a entrega dos pacotes na ordem correta nem fornece controle de fluxo ou retransmissão automática de pacotes perdidos.
O Checksum é um campo de 16bits utilizado na detecção de erros fim-a-fim em UDP. Embora o UDP forneça verificação de erros, ele não recupera esse erro. Algumas implementações de UDP simplesmente descartam o segmento danificado, outras passam o segmento errado à aplicação acompanhado de algum aviso.
Resposta : e

Algoritmos Genéticos (AGs) são técnicas de otimização e busca inspiradas no processo evolutivo natural que ocorre na natureza. Eles são uma subárea da computação evolutiva e utilizam princípios genéticos para encontrar soluções aproximadas ou ótimas para problemas complexos.
Os AGs são baseados no conceito de seleção natural, onde soluções candidatas passam por um processo de reprodução, cruzamento (recombinação) e mutação. Inicialmente, uma população de soluções é criada aleatoriamente, e a partir disso, ocorre um ciclo de geração de novas soluções. Essas soluções são avaliadas por uma função de aptidão (fitness) que quantifica sua qualidade em relação ao problema em questão.
Resposta : c

Essa pergunta é de sistemas distribuídos (segundo o gabarito), mas não tem informação alguma que ajude a identificar esse tópico no enunciado.
Transações normalmente são "tudo ou nada", ou seja, ou executamos as operações ou cancelamos o que foi alterado em caso de falha, voltando o(s) sistema(s) para um estado anterior consistente. Porém, imagine um sistema com vários nós, sendo que a execução de uma transação depende da comunicação entre eles para gravação do que vai ser modificado. Os dados podem ficar em conflito quando, por exemplo, dois nós receberam a atualização e um terceiro não. Nesses casos, pode-se reiniciar a transação ou matá-la, informando os nós do problema para que cada sistema execute localmente o que for necessário para voltar ao estado anterior.
Resposta : a

Vamos avaliar cada item:
A - A expressão regular "ab*" representa a sequência "a" seguida de zero ou mais "b". Isso significa que podemos gerar palavras como "a", "ab", "abb", "abbb", e assim por diante.
B - A expressão regular "ab" representa uma sequência de zero ou mais "a" seguida de zero ou mais "b".
C - A expressão regular "(ab)*" representa a sequência "ab" repetida zero ou mais vezes. Essa expressão permite gerar palavras como "", "ab", "abab", "ababab" e assim por diante.
D - A expressão regular "(a|b)(a|b)*" representa a sequência de "a" ou "b" seguida de zero ou mais ocorrências de "a" ou "b".
E - A expressão regular "(a|b)*" representa a sequência de zero ou mais ocorrências de "a" ou "b". Essa expressão permite gerar todas as palavras possíveis com os caracteres "a" e "b", incluindo palavras vazias, apenas "a", apenas "b" e qualquer combinação desses caracteres em qualquer ordem.
Podemos notar que a opção "E" permite gerar mais palavras do que as demais para a linguagem $\{a,b\}$.
Resposta : e

O aprendizado supervisionado é uma abordagem amplamente utilizada no campo da inteligência artificial e do aprendizado de máquina. É um tipo de aprendizado em que um modelo é treinado para aprender a mapear entradas para saídas com base em exemplos fornecidos, ou seja, em um conjunto de dados rotulados.
Alguns dos principais algoritmos usados são: Regressão, árvores de decisão, máquinas de vetores de suporte, redes neurais, KNN (K-Nearest Neighbor) e Naive-Bayes.
Resposta : d

I - O plano de qualidade é um conjunto de atributos de software que devem ser satisfeitos de modo que o software atenda às necessidades do usuário (seja ele um usuário final, um desenvolvedor ou uma organização). Aqui não deveriam entrar requisitos não-funcionais. Item incorreto.
II - Correto. O time de qualidade deve ter independência para poder analisar e reportar problemas, em um cenário ideal.
III - Correto. Em nível organizacional quer dizer para toda a organização, padronizando processos, documentos, etc...
Resposta : E