13 - Linguagens Formais, Autômatos e Computabilidade
13.1 - Gramáticas.Quando estudamos linguagens formais, interessa distinguir a estrutura sintática das cadeias do significado eventualmente associado a elas. Para a teoria formal, o foco principal está em descrever conjuntos de cadeias e os mecanismos capazes de gerá-las ou reconhecê-las.
A sintaxe trata da forma das cadeias e das regras gramaticais que definem quando uma palavra pertence a uma linguagem. A semântica, por outro lado, trata da interpretação dessas cadeias quando isso faz sentido no contexto estudado. Em teoria das linguagens, muitas vezes a sintaxe pode ser analisada independentemente da semântica.
Há diferentes formalismos para abordar linguagens e sistemas computacionais. Em linhas gerais, podemos destacar:
- Operacional: descreve como uma máquina ou reconhecedor processa uma entrada;
- Axiomático: enfatiza regras formais e propriedades dedutivas do sistema;
- Denotacional ou gerador: descreve a linguagem por regras de formação ou por objetos matemáticos associados.
Se $\Sigma$ representa um alfabeto, $\Sigma^*$ representa todas as palavras possíveis e $\Sigma^+=\Sigma^*-\{\epsilon\}$, onde $\epsilon$ é o elemento neutro (ou vazio). Uma linguagem formal, ou linguagem, é qualquer subconjunto L de $\Sigma^*$. O conjunto das partes do conjunto de palavras possível é dado por $2^{\Sigma^*}$.
Uma linguagem de programação é definida pelo conjunto de todos os programas (palavras) da linguagem.
Uma gramática é um conjunto finito de regras que, quando aplicadas em sequência, geram palavras. Uma gramática de Chomsky, gramática irrestrita ou apenas gramática é uma quádrupla ordenada $G=(V,T,P,S)$ onde
V = conjunto de símbolos variáveis ou não terminais
T = conjunto de símbolos terminais disjuntos de V
P = (V $\cup$ T)+ → (V $\cup$ T)* : é uma relação finita, dita relação de produções ou simplesmente produções. cada par é chamado de regra de produção ou apenas produção.
S = elemento distinto de V ou símbolo inicial ou variável inicial.
Regras de produção: definem as condições de geração das palavras em uma dada linguagem, ou seja, o processo de derivação com base na gramática.
Relação de derivação: par da relação de derivação, dada por $\Rightarrow$, com mesmo domínio e codomínio de P, onde um par $\langle \alpha, \beta \rangle$ representa a relação, ou na forma infixada $\alpha \Rightarrow \beta$. Uma derivação é uma substituição de uma subpalavra de acordo com uma regra de produção.
Seja L uma linguagem gerada pela gramática G, escrevemos L(G) , L=GERA(G), ou, por ex:
$L(G)=\{w\in T^*\;|\;S\Rightarrow ^+w\}$
onde $\Rightarrow^+$ indica uma ou mais derivações, e $\epsilon$ representa a palavra vazia.
Duas gramáticas $G_1$ e $G_2$ são ditas equivalentes quando geram a mesma linguagem, isto é, quando $L(G_1)=L(G_2)$.
Gramáticas regulares podem ser restritas em suas regras de produção por algumas formas. Uma delas é através de gramáticas lineares (à direita, à esquerda, unitária à direita, unitária à esquerda). Uma gramática é dita regular se é uma gramática linear. Gramáticas regulares podem ser construídas a partir de autômatos finitos determinísticos.
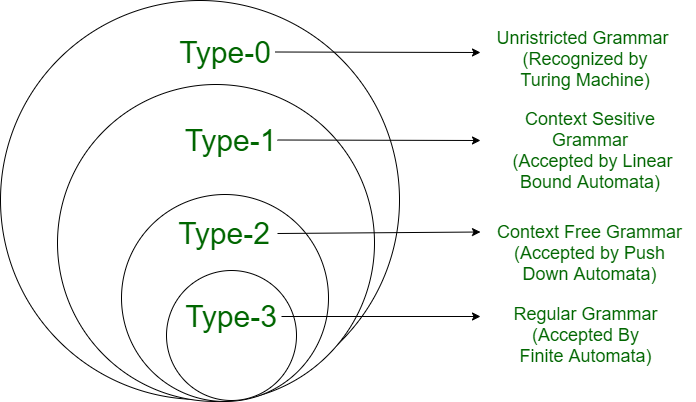
As linguagens são organizadas em hierarquias, pensadas assim originalmente pelo linguista Noam Chomsky.
Na hierarquia de Chomsky, destacam-se as linguagens regulares, as linguagens livres de contexto, as linguagens sensíveis ao contexto e as linguagens recursivamente enumeráveis.
Linguagens regulares formam uma classe relativamente simples, com reconhecedores eficientes e forte relação com expressões regulares, gramáticas regulares e autômatos finitos.
O lema do bombeamento, também conhecido como lema do bombeamento para linguagens regulares, é um importante teorema da teoria das linguagens formais e autômatos. Ele descreve uma propriedade fundamental das linguagens regulares e fornece um critério para provar que determinada linguagem não é regular.
O lema do bombeamento foi introduzido por Y. Bar-Hillel, Micha Perles e Eli Shamir. Eles estabeleceram o lema do bombeamento como uma ferramenta teórica para demonstrar a não regularidade de certas linguagens.
A ideia central do lema do bombeamento é que se uma linguagem é regular, então qualquer palavra suficientemente longa pertencente a essa linguagem pode ser dividida em partes que podem removidas ou repetidas um número arbitrário de vezes, mantendo-se dentro da linguagem. Em outras palavras, se uma palavra longa faz parte de uma linguagem regular, podemos "bombeá-la" (repetir uma parte dela) e ainda assim obter palavras válidas da linguagem.
Esta é uma ferramenta poderosa na teoria das linguagens formais, pois permite provar a não regularidade de uma linguagem de maneira relativamente simples. Ele é frequentemente usado para mostrar que certas linguagens não podem ser reconhecidas por autômatos finitos determinísticos (AFDs) ou autômatos finitos não determinísticos (AFNs), que são modelos computacionais para as linguagens regulares.
A importância do lema do bombeamento reside na sua utilidade para identificar linguagens não regulares. Ele nos fornece um critério para provar que determinada linguagem não é regular, o que é essencial para a compreensão das classes de linguagens formais. Além disso, o lema do bombeamento desempenha um papel central na teoria da computabilidade e na análise de complexidade de algoritmos.
No entanto, é importante destacar que o lema do bombeamento não é uma ferramenta geral para provar que uma linguagem é regular. Ele apenas fornece um critério para provar que uma linguagem não é regular. Existem linguagens que não satisfazem as condições do lema do bombeamento e ainda assim não são regulares.
Linguagens livres de contexto são especialmente importantes porque conseguem descrever estruturas aninhadas, como balanceamento de parênteses, blocos e árvores sintáticas, muito comuns em linguagens de programação. Também aparecem em analisadores sintáticos, tradutores e processadores de texto estruturado.
Para estudá-las utilizamos os formalismos de gramática livre de contexto e autômatos com pilhas. Além disso, os seguintes tópicos são importantes no estudo dessas linguagens:
- Árvores de derivação: Permite analisar a derivação de uma palavra onde o primeiro elemento está na raiz e o terminado em uma das folhas;
- Gramática ambígua: Estuda o comportamento quando duas ou mais árvores representam a mesma palavra;
- Simplificação de gramática: Torna mais simples um sistema de produção sem reduzir o poder gerador da gramática;
- Forma normal: Adiciona restrições rígidas sem reduzir o poder gerador da gramática.
As linguagens livres de contexto são definidas a partir de gramáticas livres de contexto, nas quais cada produção tem a forma $A\rightarrow \alpha$, com $A$ um não terminal e $\alpha$ uma palavra de $(V\cup T)^*$. O ponto central é que a substituição de $A$ por $\alpha$ independe do contexto em que $A$ aparece.
$$ GERA(G)=\{ w\in T^* \; |\; S\Rightarrow^+w \} $$Toda linguagem regular pode ser descrita por uma expressão chamada de regular, ou expressão regular, que é um tipo de formalismo denotacional ou gerador, onde inferimos a construção das palavras da linguagem alvo. Definidas as seguintes expressões como regulares $\emptyset, \{ \epsilon \}, \{x\}$ , por indução provamos que quando r e s são expressões regulares pela linguagens R e S:
- união: (r+s) é uma expressão regular e denota $R\cup S$
- concatenação: (rs) é uma expressão regular e denota $R\;S=\{ uv | u\in R \; e\; v\in S \}$
- concatenação sucessiva: $(r^*)$ é expressão regular e denota $R^*$
Uma linguagem é regular se, e somente se, é possível construir um autômato finito (determinístico ou não) que reconheça essa linguagem.
Um reconhecedor é um tipo de máquina abstrata simples que analisa se uma dada entrada é reconhecida ou não (aceita / rejeita). Os principais tipos são:
- Autômato finito
- Autômato com pilha
- Máquina de Turing
Linguagens livres de contexto são fechadas sob união, concatenação e fecho de Kleene, mas em geral não são fechadas sob interseção e complementação.
Kleene star é dada por:
$$ L^*=\cup_{n\geq0}L^n $$Operações úteis:
- Construir novas linguagens regulares a partir das existentes (define-se uma álgebra);
- Provas propriedades;
- Construir algoritmos.
Para definir se uma linguagem é regular, podemos representá-la por um dos formalismos apresentados (autômato finito, expressão regular ou gramática regular). Para saber se ela não é, pode se utilizar o lema do bombeamento (explicado nos parágrafos a seguir) para provar por absurdo.
O lema do bombeamento lida com ciclos de transição quando a palavra de entrada tem mais símbolos do que estados possíveis no autômato, mas isso não quer dizer que a palavra é rejeitada.
Entre as propriedades importantes das linguagens livres de contexto estão decidibilidade de vazio, finitude e pertinência em vários casos relevantes. Essas propriedades são estudadas por algoritmos específicos sobre gramáticas e autômatos equivalentes, e não apenas por inspeção direta do número de estados.
Também é uma propriedade importante definir quando duas linguagens regulares são iguais. Isso é feito através de um algoritmo simples, por um teorema, e a comparação das linguagens geradas por autômatos finitos.
É importante saber que formalismos utilizados nas linguagens regulares podem ser traduzidos entre si. Por exemplo, autômatos finitos determinísticos para expressões regulares ou gramáticas regulares, ou ainda para autômatos finitos não determinísticos e vice-versa.
Sempre que usamos autômatos finitos, qualquer solução obtida é ótima, exceto por eventual redundância de estados. As redundâncias de estados podem ser eliminadas pelo processo de minimização de um autômato finito, ou seja, gerar um novo autômato equivalente mas com menor número de estados. Dois autômatos tem estados equivalentes quando aceitam/rejeitam uma mesma palavra w.
Algoritmos de reconhecimento para linguagens livre de contexto:
- Autômato com pilha descendente;
- Algoritmo de Cocke-Younger-Kasami;
- Algoritmo de Earley.
Eles são classificados como top-down (ou preditivo) e bottom-up. O primeiro constrói uma árvore de derivação para a palavra de entrada pela raiz, com direção dos ramos às folhas. No último, a árvore vai no sentido contrário, em direção à raiz.
Um sistema de estados finitos é um modelo abstrato no qual o comportamento é descrito por um conjunto finito de estados e por regras de transição disparadas por símbolos de entrada. Esse modelo é muito útil para representar protocolos, analisadores léxicos e vários mecanismos de controle, embora seja limitado para tarefas que exigem memória não limitada.
Ao construirmos um sistema podemos utilizar três abordagens distintas para descrever sua composição, ou seja, como montar esquemas mais complexos de outros mais simples:
- Sequencial: O próximo componente é executado assim que o atual é finalizado;
- Concorrente: Componente independentes que executam estados sem ordem definida, ao mesmo tempo;
- Não determinista: o próximo passo pode ter múltiplas possibilidades formais de transição, sem que isso signifique aleatoriedade física no sentido usual.
Autômatos são sistemas de estados finitos que utilizam o modelo sequencial para modelar seus componentes. É muito útil para estudos teóricos em computação como compiladores, semântica formal e modelos para concorrência. São divididos em:
- Determinístico: o sistema lê o símbolo de entrada e só pode selecionar um estado subsequente;
- Não-determinístico: Há opções de escolha, onde o sistema deve executar algum processo para definir a seleção do próximo estado;
- Movimentos vazios: Sistema pode mudar de estado sem ler um símbolo associado.
É possível provar que os três tipos acima tem poder computacional equivalente.
O autômato finito determinístico (AFD) é composto de três partes:
- Fita: Entrada finita que contém o símbolo a ser lido;
- Unidade de controle: Informa o estado atual do sistema e lê a fita se movendo sempre em um sentido (definido como direita);
- Programa: Regra de transição após leitura do símbolo.
A fita não pode ser regravada (conteúdo não pode ser alterado), os símbolos ocupam toda a fita e pertencem ao alfabeto de entrada do sistema. A unidade de controle, ou controle finito, deve ler uma célula de cada vez e chamar o programa para determinar o próximo estado do autômato.
Um AFD pode ser definido por uma 5-upla ordenada $M=(\Sigma,Q, \delta, q_0,F)$ onde
- $\Sigma$ : Alfabeto de símbolos de entrada;
- $Q$ : Conjunto de estados possíveis (finito);
- $\delta$ : Programa utiliza nas transições de estado: $\delta \;: \;Q \times \Sigma \rightarrow Q$ ou $\sigma(p,a)=q$ , onde p é o estado atual e a um símbolo, gerando o novo estado q;
- $q_0$ : Estado inicial. $q_0\in Q$.
- $F$ : Subconjunto de Q que representa os estados finais.
Autômatos podem ser representados por gráficos onde
- Estados são nós, representados por círculos;
- Transições são arestas entre nós, com a marcação do símbolo utilizado;
- Estados iniciais e finais devem ser marcados como tais;
- Transições paralelas devem ser informadas com os símbolos necessários ou a regra.
Também podemos representar os AFDs por matrizes.
Como um AFD não tem memória, uma palavra w deve ser quebrada em símbolos e o programa chamado repetidas vezes para cada símbolo até a condição de parada ser detectada. Sempre deve existir uma parada porque a entrada é finita.
Qualquer AFD pode ser visto como um grafo finito direto.
São dois casos onde o AFD assume a parada de processamento:
- Após aceitar o último símbolo, vai para estado final: ACEITA;
- Após o último símbolo, vai para estado não final ou entra em estado indefinido para o parâmetro: REJEITA.
A função programa estendida é utilizada para descrever as sucessivas aplicações de uma função $\delta$ aos símbolos da palavra de entrada e serve para definir a linguagem aceita ou rejeitada pelo AFD.
Os autômatos finitos não determinísticos (AFNs) são importantes tanto em teoria quanto em construções práticas, pois frequentemente simplificam descrições formais. Qualquer AFN pode ser convertido em um AFD equivalente. No AFN, a função de transição pode devolver um conjunto de estados possíveis, e a aceitação ocorre se existir ao menos um caminho bem-sucedido de processamento.
$$ \delta=Q\times \Sigma \rightarrow 2^Q $$ou $\delta(p,a)=\{ q_1,q_2,...,q_n \}$. Se $\delta(p,a)=\emptyset$ então o AFN para e rejeita a entrada.
Qualquer AFD com movimentos vazios pode ser representado por um AFN.
As linguagens livres de contexto podem ser associadas ao formalismo de autômatos com pilha, que é uma modificação do autômato finito, adicionando-lhe memória auxiliar. O armazenamento pode ser tão grande quanto se queira e esse modelo é útil para resolver problemas que não eram possíveis com AFD ou AFN. Qualquer linguagem livre de contexto pode ser reconhecida por um autômato com pilha, sendo a estrutura de memória suficiente para organizar os estados. A pilha começa inicialmente vazia (exceto pelo símbolo inicial de marcação) e o autômato para quando for aceito um estado final. Semelhante ao AFD, há quatro partes no autômato de pilha:
- Fita
- Pilha
- Unidade de controle: agora com cabeça de fita e de pilha
- Programa: Lê a fita e pode gravar na fita o estado da máquina.
A pilha segue a estrutura de dados de mesmo nome, sendo que o elemento no topo é o primeiro a ser removido e é removido após esse passo.
Esse formalismo ainda pode ser modificado para aceitar múltiplas pilhas. No caso de um autômato com duas pilhas, temos um poder computacional similar à máquina de Turing, que é o dispositivo mais geral de computação. Se um problema é solucionado por um autômato com mais de duas pilhas, então é solucionado por um com duas pilhas.
Em 1936, Alan Turing introduziu um formalismo abstrato de computação que hoje ocupa papel central na teoria da computação. Uma máquina de Turing possui uma fita potencialmente ilimitada e um mecanismo de leitura, escrita e movimento, servindo como modelo geral de computação algorítmica.
As linguagens reconhecíveis por máquinas de Turing são chamadas recursivamente enumeráveis, ou linguagens de tipo 0 na hierarquia de Chomsky. As gramáticas correspondentes são as gramáticas irrestritas.
Nem toda computação de uma máquina de Turing precisa terminar. Há entradas para as quais a máquina pode executar indefinidamente. O subconjunto de linguagens para as quais existe uma máquina que sempre para e decide aceitação ou rejeição é a classe das linguagens recursivas, também chamadas decidíveis.
As linguagens sensíveis ao contexto podem ser reconhecidas por máquinas de Turing linearmente limitadas, isto é, máquinas cuja fita de trabalho é limitada por uma função linear do tamanho da entrada.
Na fita, os seguintes são os símbolos válidos:
- Pertence ao alfabeto de entrada;
- Pertence ao alfabeto auxiliar;
- Ser “branco”;
- Ser “marcador de início de fita”.
A unidade de controle pode se mover para direita ou esquerda na fita, ler e gravar um símbolo, sendo que esses movimentos são determinados pelo programa.
Definição: Uma máquina de Turing (MT) é uma 8-upla $M=(\Sigma,Q,\delta,q_0,F,V,\beta,\star)$, onde
- $\Sigma$ : alfabeto de símbolos de entrada;
- Q : conjunto de estados possíveis;
- $\delta$ : função programa. $\delta :Q\times (\Sigma \cup V\cup \{\beta, \star\})\rightarrow Q \times (\Sigma\cup V\cup\{\beta,\star\})\times \{E,D\}$, onde E e D são esquerda e direita respectivamente, ou, de forma resumida: $\delta (p,x)=(q,y,m)$ , onde q é o novo estado, y o símbolo gravado e m o sentido do movimento.
- $q_0$ : estado inicial
- F : subconjunto de Q, ou estados finais.
- V : alfabeto auxiliar (pode ser vazio)
- $\beta$ : símbolo especial branco
- $\star$ : símbolo de início ou marcador de fita.
A máquina vai executar sucessivamente a função programa até incorrer em uma parada. Como dito anteriormente, há a possibilidade de loops infinitos.
Uma linguagem L dita recursiva é tal que existe ao menos uma máquina de Turing que Aceita(M) = L, ou Rejeita(M) = ~L, onde ~L é o complemento de L.
Há modelos equivalentes à maquina de Turing, de mesmo poder computacional, como:
- Autômato com múltiplas pilhas;
- Máquina de Turing não determinística;
- Máquina de Turing com fita infinita à esquerda e à direita;
- Máquina de Turing com múltiplas fitas;
- Máquina de Turing multidimensional;
- Máquina de Turing com múltiplas cabeças;
- Combinações de modificações sobre a máquina de Turing.
É composta das linguagens regulares ou tipo 3, livres de contexto ou tipo 2, sensíveis ao contexto ou tipo 1 e recursivamente enumeráveis ou tipo 0.
No estudo da computabilidade, funções recursivas são uma das maneiras clássicas de formalizar a noção de função efetivamente computável sobre os números naturais. Elas estão intimamente relacionadas ao cálculo lambda e às máquinas de Turing.
Uma função recursiva parcial corresponde, em termos intuitivos, a uma função que pode ser computada por um procedimento que talvez não termine para todas as entradas. Quando o procedimento sempre termina, falamos em função recursiva total.
A tese de Church-Turing, formulada na década de 1930 por Alonzo Church e Alan Turing, é um princípio fundamental na ciência da computação que diz respeito à natureza dos problemas que podem ser resolvidos (ou "decididos") por computadores. Embora não seja uma teoria formalmente provada, a tese tem sido amplamente aceita e utilizada como um guia na pesquisa de computação e matemática.
Contexto Histórico
No início do século 20, matemáticos e lógicos começaram a explorar os limites do que poderia ser computado. Questões sobre decidibilidade, ou seja, se certos problemas matemáticos podem ter uma solução definitiva encontrada por meio de um procedimento algorítmico, tornaram-se centrais. Em 1931, Kurt Gödel publicou seus teoremas de incompletude, mostrando que existem afirmações verdadeiras em sistemas formais que não podem ser provadas dentro desses sistemas. Isso lançou dúvidas sobre a capacidade de resolver todos os problemas matemáticos por meio de métodos computacionais. Todo esse desenvolvimento surgiu dos 23 problemas de Hilbert, propostos em 1900. O décimo problema questionava se existia um procedimento algorítmico para determinar a solubilidade de equações diofantinas arbitrárias. Uma equação diofantina é uma equação polinomial com coeficientes inteiros para a qual se busca soluções inteiras. A questão de Hilbert, portanto, indagava sobre a possibilidade de decidir, de forma geral e sistemática, se dadas equações desse tipo têm solução inteira.
Tentativas IniciaisInicialmente, as tentativas de resolver o décimo problema de Hilbert concentraram-se em desenvolver métodos específicos para classes particulares de equações diofantinas. Ao longo das primeiras décadas do século XX, diversos matemáticos contribuíram com avanços significativos para o estudo de equações diofantinas, embora um método geral e abrangente para todas as equações parecesse cada vez mais inatingível.
Contribuições de Church e Turing
-
Alonzo Church: Em 1936, Church introduziu o conceito de funções recursivas e o cálculo lambda, uma forma de representar algoritmos e funções computáveis. Ele propôs que as funções efetivamente calculáveis são precisamente aquelas que podem ser definidas no cálculo lambda, formulando a noção de "decidibilidade" em termos de computabilidade.
-
Alan Turing: No mesmo ano, Turing introduziu o conceito de uma máquina abstrata, agora conhecida como Máquina de Turing, capaz de simular qualquer processo de cálculo algorítmico. Ele argumentou que esta máquina poderia modelar o processo de cálculo humano, seguindo um conjunto de instruções simples. Turing usou sua máquina para resolver o "Entscheidungsproblem" (problema de decisão) proposto por David Hilbert, mostrando que não existe um algoritmo geral que possa decidir a verdade ou falsidade de todas as afirmações matemáticas. Esse resultado destacou limitações fundamentais na decidibilidade matemática.
Tese de Church-Turing
A tese de Church-Turing é uma hipótese sobre a natureza da computabilidade mecânica. Ela postula que uma função sobre os números naturais pode ser calculada por um algoritmo se, e somente se, ela pode ser computada por uma Máquina de Turing. Em outras palavras, ela estabelece que o conceito de "computável" é equivalente a ser calculável por esses meios teóricos. Essa tese não foi originalmente formulada como um teorema a ser provado, mas sim como uma noção intuitiva baseada nas observações de Church e Turing sobre a natureza do cálculo algorítmico.
Impacto na Decidibilidade
A tese de Church-Turing tem implicações profundas para a teoria da decidibilidade. Ela fornece uma base para entender quais problemas são computacionalmente solúveis e quais permanecem indecidíveis. Por exemplo, o problema da parada, que pergunta se uma dada máquina de Turing vai parar ou continuar a rodar indefinidamente para uma entrada específica, é um problema clássico que foi provado ser indecidível por Turing. Isso significa que não existe um algoritmo geral que possa determinar, para qualquer máquina de Turing e entrada, se a máquina eventualmente para ou não.
Na teoria da computação, um dos tópicos mais fascinantes é o estudo de problemas indecidíveis - questões para as quais não existe um algoritmo que possa fornecer uma resposta correta para todas as possíveis entradas. Este campo explora os limites do que pode ser resolvido por máquinas e algoritmos, lançando luz sobre a natureza fundamental da computação.
Linguagens DecidíveisUma linguagem é dita decidível se existe uma máquina de Turing que sempre para e responde corretamente se a entrada pertence ou não à linguagem. Isso é diferente de ser apenas recursivamente enumerável, caso em que a máquina pode aceitar entradas da linguagem, mas eventualmente entrar em loop para entradas fora dela.
O Problema da Parada e o Método de DiagonalizaçãoO problema da parada é um dos problemas mais famosos em teoria da computação e foi introduzido por Alan Turing em 1936. Este problema pergunta se é possível criar um algoritmo que, dado como entrada qualquer programa de computador e uma entrada para esse programa, determinará corretamente se o programa para ou continua a executar indefinidamente para essa entrada. Turing provou que tal algoritmo não pode existir, utilizando um argumento conhecido como método de diagonalização. Este método envolve a criação de uma tabela imaginária onde as linhas representam programas e as colunas representam entradas possíveis. Ao tentar construir um programa que decida o problema da parada, chegamos a uma contradição, pois tal programa teria que ser capaz de decidir sua própria parada, o que é impossível.
Linguagem Turing-irreconhecívelUma linguagem é dita Turing-irreconhecível se não existe uma máquina de Turing que possa reconhecer as strings na linguagem. Para tais linguagens, não apenas não podemos decidir se uma string específica pertence à linguagem, como também não podemos construir uma máquina de Turing que liste todas as strings que pertencem à linguagem (ou seja, não são recursivamente enumeráveis). Um exemplo de uma linguagem Turing-irreconhecível é o complemento do problema da parada, que consiste em todas as strings que não descrevem máquinas de Turing que param em uma determinada entrada. Esse resultado mostra os limites inerentes do que nossos algoritmos podem alcançar, independentemente de quão poderosos ou sofisticados eles sejam.
Estudar problemas indecidíveis nos ajuda a entender os limites fundamentais da computação, mostrando que existem perguntas que estão além do alcance de qualquer máquina de calcular, não importa quão avançada ela seja. Esses conceitos não apenas fundamentam a ciência da computação teórica mas também influenciam a forma como abordamos problemas práticos em áreas como verificação de software, inteligência artificial e além, reforçando a importância de reconhecer as fronteiras do que é computacionalmente possível.
Primeiro teorema: Nenhum sistema consistente de axiomas, onde os teoremas podem passar por um procedimento de listagem (um algoritmo por exemplo), pode provar todas as proposições verdadeiras sobre a aritmética. Corolário: Sempre há afirmações verdadeiras, mas que não podem ser provadas.
Segundo Teorema: Uma teoria, dita recursivamente enumerável e que pode provar certas proposições aritméticas básicas, além de enunciados da teoria da prova, só pode provar sua consistência se, e somente se, for inconsistente.
Quando falamos sobre complexidade de algoritmos, queremos entender como os recursos necessários para resolver um problema crescem com o tamanho da entrada. Em complexidade, é comum estudar classes inteiras de problemas, e não apenas algoritmos isolados.
Temos três classes básicas de problemas computacionais:
- Otimização: Lida com casos que pedem máximo ou mínimo de algum objeto;
- Busca: Queremos encontrar um objeto com determinadas propriedades em alguma estrutura;
- Decisão: Informa se proposição admite resposta do tipo “sim” ou “não”.
Há ligações entre os três problemas, isto é, podemos converter a resposta de uma classe para outra. Em um caso ideal, o algoritmo criado deve informar se o problema é intratável ou retornar sua solução, mas na maioria das vezes este não é caso. Muitos problemas não são possíveis nem mesmo de saber se tem uma solução.
Chamamos de classe P o conjunto dos problemas de decisão que podem ser resolvidos por um algoritmo determinístico em tempo polinomial no tamanho da entrada. Em teoria da complexidade, essa classe é frequentemente usada como aproximação formal da ideia de problema tratável.
A classe NP é o conjunto dos problemas de decisão cujas soluções candidatas podem ser verificadas em tempo polinomial por uma máquina determinística, ou, de forma equivalente, podem ser resolvidos em tempo polinomial por uma máquina não determinística.
A questão P = NP pergunta se todo problema cuja solução pode ser verificada eficientemente também pode ser resolvido eficientemente. Até hoje, essa questão permanece em aberto.
Dentro de NP, alguns problemas se destacam por sua centralidade. Um problema é NP-difícil se todo problema em NP pode ser reduzido a ele em tempo polinomial. Um problema é NP-completo se, além de NP-difícil, ele próprio pertence a NP.
Se algum problema NP-completo estiver em P, então P = NP. Se nenhum problema NP-completo estiver em P, então P ≠ NP.
O artigo seminal de Stephen Cook, intitulado "The Complexity of Theorem-Proving Procedures" (A Complexidade dos Procedimentos de Prova de Teoremas), foi apresentado no Terceiro Simpósio Anual da ACM sobre Teoria da Computação em 1971. Este trabalho inovador introduziu o conceito de NP-completude, estabelecendo a estrutura fundamental para o campo da complexidade computacional.
No seu artigo, Cook definiu uma classe de problemas conhecidos como "NP-completos", que são problemas em NP que são pelo menos tão difíceis quanto qualquer outro problema em NP. Ele introduziu a noção de que se qualquer problema NP-completo pudesse ser resolvido em tempo polinomial, então todos os problemas em NP também poderiam ser resolvidos em tempo polinomial, mostrando efetivamente que P = NP. Este conceito se baseia na ideia de que os problemas NP-completos são uma espécie de "pedra angular" na compreensão da estrutura de NP.
A principal contribuição do artigo de Cook foi a identificação do primeiro problema que ele provou ser NP-completo: o problema da satisfabilidade booleana (SAT). SAT pergunta se uma fórmula booleana dada pode ser tornada verdadeira atribuindo valores verdadeiros às suas variáveis. Cook mostrou que SAT é NP-completo ao demonstrar uma redução em tempo polinomial de qualquer problema em NP para SAT. Isso significa que resolver SAT em tempo polinomial implica que todos os problemas em NP também podem ser resolvidos em tempo polinomial.
A importância do artigo de Cook não pode ser superestimada. Foi o primeiro a articular formalmente o problema P vs. NP e a identificar um exemplo concreto de um problema NP-completo. O trabalho de Cook abriu a porta para uma compreensão mais ampla da complexidade computacional e influenciou diretamente o desenvolvimento do campo. Após seu artigo, a identificação e o estudo de problemas NP-completos se tornaram um foco central da ciência da computação, levando à descoberta de muitos outros problemas NP-completos em vários domínios.
O artigo de Cook não apenas introduziu uma nova maneira de pensar sobre problemas computacionais, mas também preparou o terreno para pesquisas subsequentes na área. O conceito de NP-completude desde então se tornou uma ferramenta fundamental para entender a dificuldade dos problemas computacionais e para classificá-los com base em suas complexidades computacionais inerentes.
As contribuições de Stephen Cook foram reconhecidas com o Prêmio Turing em 1982, uma das maiores honrarias em ciência da computação, por seu trabalho sobre a teoria da complexidade computacional e, em particular, por seu artigo sobre a complexidade dos procedimentos de prova de teoremas.
Na teoria da computação, a redutibilidade é um conceito chave que permite comparar a complexidade de diferentes problemas, estabelecendo uma forma de "traduzir" um problema em outro. Essencialmente, se um problema A pode ser reduzido a um problema B, qualquer solução para B pode ser usada para resolver A, implicando que A não é mais difícil de resolver do que B. Este conceito é crucial para entender as relações entre diferentes classes de problemas e para identificar problemas intrinsecamente difíceis. Vamos explorar dois métodos importantes de redutibilidade: redução via histórias de computação e redutibilidade por mapeamento.
Teoria das Linguagens e Redução via Histórias de ComputaçãoA teoria das linguagens na computação lida com o estudo de linguagens formais e suas propriedades computacionais. Dentro deste contexto, a redução via histórias de computação é uma técnica que permite reduzir um problema de decisão (determinar se uma entrada pertence a uma linguagem específica) a outro, utilizando a "história" de uma computação como ponte entre eles. Uma história de computação é essencialmente um registro dos estados por que uma máquina de Turing passa ao processar uma entrada.
Por exemplo, se queremos provar que um problema A é NP-completo, podemos tentar reduzi-lo a um problema B já conhecido por ser NP-completo, mostrando que qualquer instância de A pode ser transformada em uma instância de B de forma que a solução de B nos dê a solução para A. Para fazer isso, podemos construir uma máquina de Turing que simula a execução de A, e usar a história dessa computação para criar uma instância de B. Essa abordagem é particularmente útil para provar a NP-completude de problemas, demonstrando que eles são, pelo menos, tão difíceis quanto os problemas mais difíceis em NP.
Redutibilidade por MapeamentoA redutibilidade por mapeamento é outra técnica fundamental na teoria da computação, que envolve a construção de uma função computável (ou mapeamento) que transforma instâncias de um problema A em instâncias de um problema B de tal forma que a resposta para a instância transformada de B corresponda diretamente à resposta da instância original de A. Este tipo de redutibilidade é especialmente importante para o estudo da complexidade computacional, pois permite classificar problemas com base em sua dificuldade relativa.
A redutibilidade por mapeamento é comumente usada para demonstrar que certos problemas são indecidíveis, mostrando que se pudéssemos resolver um determinado problema (como o problema da parada), então seríamos capazes de resolver outro problema que já sabemos ser indecidível. Da mesma forma, é uma ferramenta essencial para estabelecer a NP-completude, onde uma função de redução por mapeamento transforma instâncias de um problema conhecido por ser NP-completo em instâncias do problema em questão, demonstrando assim que este último é pelo menos tão difícil quanto o primeiro.
Ambas as formas de redutibilidade, via histórias de computação e por mapeamento, são pilares fundamentais na análise da complexidade dos problemas na teoria da computação. Elas não apenas ajudam a classificar problemas em termos de sua dificuldade computacional mas também oferecem insights sobre a natureza da computabilidade e os limites do que pode ser alcançado através de algoritmos.
Referências:
- Introdução à teoria da computação - Michael Sipser
- Linguagens Formais e autômatos - Paulo Blauth Menezes
- Problemas NP-Completo
- Propriedades das Linguagens Livres do Contexto
- General Recursive Function
- Undecidable problems